
Share to ...
Copy Link
Similar list
robogood2*****aster | 1K followers telegram account
31 months aged
@*****aster

Followers
1K

Posts
282

Price(USD)
$111,111

Category
Architecture & Interior

Date of Joined
Nov 2023

Date of Last Post
Apr 6, 2026
Last 100 posts

texts
89
Pictures
8

Videos
0

audios
0

documents
3
animations
0
Last 100 posts
Averages
Views
3.6K
Post/Per Month
0
Total Reactions

Total
1.1K
Post/Per Month
Besties
درود و وقت همگی بخیر امیدوارم حالتون خوب باشه. بچه هایی که تازه کار هستن و #Backend رو مدت کمی هست کار میکنن ممکنه یکم براشون سوال باشه که به صورت کلی یک سیستم چه چیزهایی رو دارد و چطور این ها باهم کار میکنند. به جواب رسیدن برای هرکدوم از این سوال ها زمان زیادی ممکنه از ادم بگیره اگر راهنما خوبی هم وجود نداشته باشه. پیشنهاد میکنم این دوره رو حتما ببینید. https://downloadly.ir/elearning/video-tutorials/system-design-for-beginners/ بهتون دید خیلی خوبی میده که چه چیزایی رو حداقل باید بدونید و میتونه به عنوان یک Roadmap هم بهش نگاه کنید که در آینده در هرکدوم از بخش های مختلف این آموزش عمیق تر بشید. اگر باتجربه تر هم هستید و سیستم دیزاین نیاز به refresher دارید یا کلا تا حالا کار نکردین شروع خوبی میتونه باشه.
22

2.3K
60
4
Top 10 Hashtags
Description
No Data
Last Posts
گر چرخ گردون گر دو روزی بر مراد ما نرفت دائما یکسان نباشد حال دوران غم مخور
12
3
559
2
2
یوتیوب چطوری از 2.49 میلیارد کاربر با MYSQl پشتیبانی میکنه؟ تو این مقاله میتونید بخونید https://newsletter.systemdesign.one/p/vitess-mysql @DevTwitter
4
678
12
#Work https://www.linkedin.com/posts/sina-abd_%D8%B3%D9%84%D8%A7%D9%85-%D8%AF%D9%88%D8%B3%D8%AA%D8%A7%D9%86-%D9%85%D8%A7-%D8%AF%D8%B1-%D9%85%D8%AC%D9%85%D9%88%D8%B9%D9%87-%D8%A7%D8%B3%D8%AA%D8%A7%D8%B1%D8%AA%D8%A7%D9%BE-%D9%85%D9%81%DB%8C%D8%AF-%D9%86%DB%8C%D8%A7%D8%B2-activity-7188140632916324352-EsUH?utm_source=share&utm_medium=member_desktop
2
802
1
🔥یک خبر خیلی داغ مربوط به ۲ دقیقه پیش. سازمان حج و زیارت هک شد. یعنی کلا اطلاعات شخصی ما ایرانی ها داخل سرویس ها ایرانی open source هست و هردوطرف کارفرما و برنامه نویس صدرصد مقصر این موضوع هستند به نظر من. https://t.me/irleaks/24
9
822
5
14

PLACEHOLDER_DOCUMENT_URL
2
822
1
سوال مصاحبه درمورد #NestJS شما وقتی با #NestJS و #TypeScript در حال توسعه #BackEnd هستید خب به صورت روتین از Injectable ها در #NestJS استفاده میکنید. حالا با فرض این که ما یک EmailService داریم که Injectable هست و میخوایم در سرویس پایین اون رو inject کنیم و استفاده کنیم. به کد پایین دقت کنید. @Injectable() class MyService { constructor(private readonly emailService : EmailService) } اینجا همه چی درست و عادی کار میکنه ولی اگر یکم با دقت بیشتری نگاه کنید این کد خیلی غیر عادی هست. باتوجه به این موضوع که در هنگام transpile شدن کد #TypeScript به #JavaScript تایپ ها حذف میشه. حالا سوال اینجا هست که #NestJS چطور با استفاده از یک type یعنی EmailService متوجه میشه باید چه سرویسی رو inject کنه؟ در حقیقت اینجا از یک type یک logic داره که در برنامه ما استفاده میشه و برسی این black magic میتونه جذاب باشه. نظراتتون رو کامنت کنید. #Tip
13
830
4
11
خب ظاهرا در جهت ورژن جدید Express 5 حرکت های جدی داره صورت میگره که میتونید در این github issue اون رو پیگیری کنید. https://github.com/expressjs/discussions/issues/233 #NodeJS
8
844
3
من یک نظر دارم که استفاده از switch statement به شدت کد رو کثیف میکنه و هروقت کد #backend یا #frontend میبینم که استفاده شده حس خوبی نمیگیرم. چندین سال هست که به جرات میتونم بگم شاید ۱۰ بار switch statement استفاده نکردم مگر روی legacy کدی باشم که همچین استایلی کد زده شده باشه. دوست دارم نظر شما هم بدونم که چه فکر میکنید. https://x.com/imanhpr_media/status/1785700265280102807?t=kv4Mr2FE8_CIDVl__IqclQ&s=09
11
6
848
3
45
چند وقت پیش یک همچین پستی گذاشته بودم که در هنگام تست نوشتن با همچین کدی روبرو شده بودم 3 === new Number(3) جواب این false میشه و یکم برام عجیب بود دوستان هم توضیحات خوبی دادن منطقی و درست بود ولی کامل جوابم رو نگرفتم که چرا اینطوره. شما اگر قصد دارید با استفاده از function هایی مثل String, Boolean, Number عملیات type conversion انجام بدید اگر از new استفاده کنید در حقیقت typeof برابر با object میشه و کاملا منطقی هست به این دلیل که باهاش مثل constructor function رفتار میشه. حالا object که از این حالت بدست میاد شبیهه به primitive ها رفتار میکنه ولی در همچین سناریویی تفاوت خودش رو نشون میده. دلیل این رفتار هم بخاطر موضوعات تاریخی مربوط به #JavaScript هست و این موضوع هم درنظر داشته باشید که در code base های بروز اصلا منطقی نیست از این موضوع استفاده کنید و کاملا از این موضوع فرار کنید. فقط گاهی ممکن هست بهش بر بخورید پس دونستن این موضوع میتونه بهتون کمک کنه #Tip
18
862
داشتم طبق عادت stackoverflow میگشتم دنبال نکته جدید برای یادگیری. به یک سوال خوردم و وقتی روش وقت گذاشتم حس کردم یک باگ روی #NodeJS هست و رفتار منطقی نمیبینیم و خب بقیه هم ظاهرا به همین نکته رسیدن اون سوال باعث ایجاد یک issue روی #NodeJS core شد اگر دوست داشتید نگاهی به سوال بندازید و برسیش کنید خیلی جذاب بود. سوال: https://stackoverflow.com/questions/78630248/how-to-properly-abort-node-readline-promise-question گیت هاب: https://github.com/nodejs/node/issues/53497
7
872
7
4
خواستم تشکر کنم بابت گذاشتن این پست داخل چنلت. ایدی خودت رو پیدا نکردم گفتم اینجا تشکر کنم🧡 https://t.me/Never_Forget_Semicolon
6
914
مرسی از دوستانی که در بحث مربوط به این موضوع شرکت کردند. یکی از دوستان یک ویدیو خوب مربوط به این موضوع هست اشاره کرد دوست داشتید ویدیو رو ببینید جالب هست. https://www.youtube.com/watch?v=NcaiHcBvDR4
917
5
15
یکی دیگ از API های جالبه 'node:perf_hooks' استفاده از measure فانکشن هست که به ما در نهایت یک PerformanceMeasure obj برمیگردونه. این پست خیلی به پست قبل مرتبط هست پس حتما اول اون رو بخونید. https://t.me/NodeMaster/206 به مثال پست قبل اگر دقت کنید ما با استفاده از mark یک سری مارک مشخص میکنیم تا اون لحظه رو به صورت دقیق ثبت کنیم. حالا اگر بخوایم در دقیق ترین حالت ممکن duration رو اندازه گیری کنیم اینجا measure به کمک ما میاد. import { performance } from "perf_hooks"; import { setTimeout } from "timers/promises"; function myLogic() { // Complex logic return setTimeout(3000, "Hello NodeMaster"); } const perf1 = performance.mark("start_perf_check"); await myLogic(); const perf2 = performance.mark("end_perf_check"); const mes = performance.measure( "logicDuration", "start_perf_check", "end_perf_check" ); console.log(mes); در اینجا ما به عنوان arg اول یک نام برای measure مشخص میکنیم و در نهایت اسم startMark و endMark رو بهش پاس میدیم و نتیجه به صورت زیر میگیریم. PerformanceMeasure { name: 'logicDuration', entryType: 'measure', startTime: 21.1939, duration: 3004.3700479999998 } کلاس PerformanceMeasure مثل PerformanceMark پست قبل یک subclass از performanceEntry هست و entryType در این حالت همیشه measure هست. حالت های دیگ استفاده از این فانکشن بدون endMark هست که در این حالت خود فانکشن مثل endMark عمل میکنه و در صورتی که هیچ mark در نظر نگیریم startTime با مقدار 0 هست و duration لحظه ای رو نشون میده که از شروع برنامه گذشته تا به اون measure رسیده. #Tip #NodeJS
4
920
2
یکی از نکاتی که به برای بچه های #BackEnd و #FrontEnd به اندازه هم میتونه کاربردی باشه استفاده از static method های Array.from و Array.fromAsync. این نکته هم بگم که Array.fromAsync به تازگی با توجه به آپدیت #V8 در نسخه 22 برای #NodeJS منتشر شده و در نسخه های قبل در دسترس نیست. حالا کار این متد ها به چه شکل هست با .from شروع میکنیم. شما اگر یک iterable obj داشته باشید شاید بخواید این Object رو تبدیل به Array کنید و معمولا از این تکنیک استفاده میشه. const arr = []; for (const v of iterableObj) { arr.push(v); } این استایل از برنامه نویسی بیشتر به نوعی imperative programming محسوب میشه و در زبان های procedural programming خیلی دیده میشه. با این حال که #JavaScript یک زبان Multi-paradigm هست و این استایل کد زدن مجاز هست ولی خیلی در کامینیوتی مرسوم نیست و کلا بیشتر کد های declarative و ترکیب OOP و Functional استفاده میشه. ( هرچند Functional خالص سخت هست در #JavaScript ) حالا اگر بخوایم کد بالا رو یطوری داشته باشیم که مرسوم تر باشه بین برنامه نویس های #JavaScript، در این سناریو متد های Array.from و Array.fromAsync به کمک ما میاد تا کد ما declarative تر بشه. حالا برای تبدیل کد بالا کافی هست این کار رو کنید و بووم تمام! const arr = Array.from(iterable); اگر بخوام درمورد Array.fromAsync هم بگم این هست که دقیقا به همین شکل کار میکنه و تنها تفاوتش این هست که با async iterable ها و generator ها سازگار هست. const arr = []; for await (const v of asyncIterable) { arr.push(v); } حالا همین رو به این شکل تبدیل میکنیم. const arr = await Array.fromAsync(asyncIterable); هنوز یک قسمت جالب از داستان مونده بزارید با مثال بهتون نشون بدم. Array.fromAsync( new Set([Promise.resolve(1), Promise.resolve(2), Promise.resolve(3)]), ).then((array) => console.log(array)); // [1, 2, 3] اگر اینجا دقت کنید میبینید که میتونه سناریو مناسبی برای استفاده از Promise.all باشه ولی استفاده نشده به نظرتون تفاوت چیه؟ با استفاده از Promise.all تمام Promise ها به صورت همزمان تلاش به resolve شدن دارن یعنی داره concurrent انجام میشه اما در این سناریو بدون بلاک شدن event loop به ترتیب Promise ها resolve میشن. راستی این ویژگی هم از نسخه 1.38 روی #Deno در دسترس بوده و این برای من خیلی جذابه که تیم #Deno اینقدر خوب دارن عمل میکنن. مدتی هست هر حرکتی در اکوسیستم اتفاق میافته #Deno از پرچم داران در سرعت آپدیت و رو به جلو حرکت کردن هست. #Tip
22
921
8
4
سناریویی رو تصور کنید که یک پروژه مالی Deploy دارید و قصد دارید آپدیت جدید Production رو Deploy کنید و این سرویس هم ترافیک زیادی رو دریافت میکنه. اتفاقی که میافته این هست که Process قدیمی Kill میشه و یک Process با آپدیت جدید باز میشود که خیلی ساده هست. حالا موضوعی که باید توجه ویژه بشه این هست که این سرویس ترافیک زیادی داره و Kill کردن Process به صورت یهویی ممکنه در روند Transaction های موجود اختلال ایجاد کنه که به هیچ عنوان قابل قبول نیست. در بهترین حالت برای حل این چالش باید راهی داشته باشیم که تمام Transaction های جاری نهایی بشن ولی هیچ Request جدید از سمت کلاینت ها دریافت نشه. حالا برای پیاده سازی این موضوع باید چیکار کنیم؟ راه حل خیلی ساده هست. در این حالت به عنوان مثال با فرض این که application ما از طرف kubernetes سیگنال SIGTERM دریافت میکنه کافیه که server.close رو استفاده کنیم و در callback مربوط بهش از Process خارج بشیم. وقتی server.close اجرا میشه سرور دیگه ریکوست جدید دریافت نمیکنه و سعی میکنه response برای request های درحال پردازش ارسال کنه و در نهایت بعد از به پایان رسیدن تمامی request ها وارد callback میشه. import http from "node:http"; import process from "node:process"; const server = http.createServer((_, res) => res.end("NodeMaster")); process.on("SIGTERM", () => { server.close((err) => { if (err) process.exit(1); process.exit(0); }); }); server.listen(3000); کلا این مفهوم Graceful shutdown رو باید همیشه در Apllication هایی که توسعه میدین رو در نظر بگیرید و این موضوع رو داخل 12factor هم میبینید که بهش اشاره شده. گاهی اوقات توجه نکردن به Graceful shutdown میتونه با توجه به داشتن Side effect خیلی ترسناک بشه مثل کار کردن با در پروژه های realtime که میتونه باعث data lost بشه.
21
932
18
29
هرچقدر از زیبایی این بگم کم گفتم. #Clang https://youtu.be/tas0O586t80?feature=shared
8
938
6
8
#Work https://www.linkedin.com/posts/mojtaba-zolfaghary_aekagvaevahyabraecaeiaesahy-aepaebaesaewaexaepaet-activity-7195744419856211969-eIgE?utm_source=share&utm_medium=member_desktop
2
949
1
1
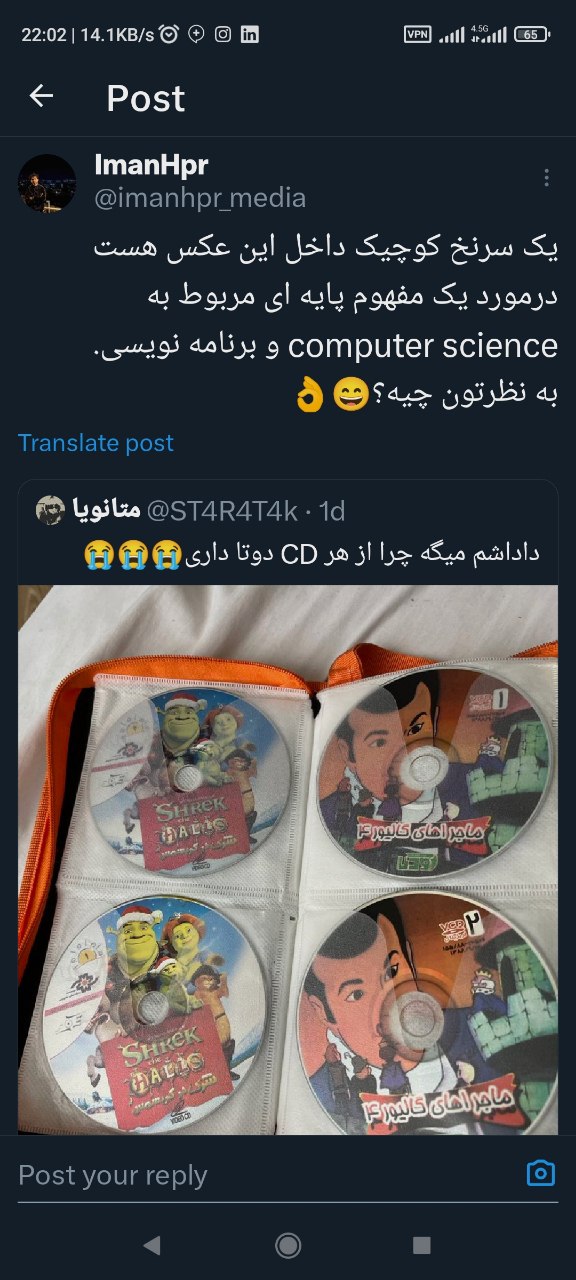
هدف از این پست ایجاد کنجکاوی در شما هست. یک مفهوم low level مربوط به computer science داخل این عکس هست. بگردید پیدا کنید بخونید یاد بگیرد. و از مسیر لذت ببرید. موفق باشید دوستان👍 https://x.com/imanhpr_media/status/1824874084511150256?t=hFiFIQitnXNBIi_I80Z3PQ&s=19
952
2
53
سلام و ارادت دوستان. این پست تبلیغ نیست. یکی از دوستان من مدتی هست داره فعالیت میکنه و کلی ویدیو آموزشی یوتیوب گذاشته و الان دوره #NestJS ایشون کامل هست. و این که یکسری مجموعه وبینار هم برگزار میکنه و در حال حاظر درحال برسی Design pattern ها هستن. یک سر به چنلش بزنید اگر حس کردید میتونه کمکتون کنه حتما ازش سوال بپرسید خوشحال میشه. https://t.me/mostafaeffatiofficial
17
971
8
1
درود دوستان امیدوارم حالتون خوب باشه. یک ویژگی خیلی کوچیک #Python داشت که من همیشه دلم میخواد داخل #NodeJS ببینم. این ویژگی خیلی وقته روی #Deno هست ( فکر کنم #BunJS هم داره ). واقعا جای خالیش رو من حس میکردم. و بلاخره این ویژگی رو به صورت Experimental در آپدیت 22.18 دیدیم که اضافه شد. برا این که وارد بحث بشیم دوست دارم با این کد پایتون شروع کنم. def main(): print("Hello From Main Function") if __name__ == "__main__": main() توضیح کد خیلی ساده هست که با استفاده از این پترن میشه تشخیص داد آیا این بخش از code که داره اجرا میشه آیا import شده توسط یک ماژول دیگه یا ماژول اصلی هست که باهاش برنامه رو اجرا کردن؟ اگر ماژول اصلی باشه که برنامه رو run کردن فانکشن main رو اجرا میکنه برنامه وارد main routine خودش میشه. شاید فکر کنید داخل زبانی مثل #Python و #JavaScript اینکار احمقانه باشه باتوجه به این که هر expressionـی رو میتونیم داخل top level خودمون اجرا کنیم. پس مزیت این کار چیه؟ جواب این هست که باتوجه به این که ما برنامه رو مینویسیم خب ما میدونیم کجا main routine رو اجرا کنیم ولی تصور کنید روی یک code base بزرگ رفتین و دنبال entrypoint میگردید. در این سناریو میتونه به عنوان داکیومنتیشن مناسب باشه. یا زمانی بخواید کدی رو اجرا کنید که فقط و فقط اگر کسی اون ماژول رو import کرده باشه و ... . همین الان هم وقتی پروژه #NestJS دارید bootstrap function دقیقا داره نقش main routine رو بازی میکنه و شما حتما باید اون رو اجرا کنید که برنامتون اجرا بشه. معمولا داخل #NestJS همچین چیزی میبینیم function bootstrap() { // init app } bootstrap(); سناریویی رو در نظر بگیرد به هر دلیلی میخواید از این main.js یک چیزی رو import کنید( هرچند اگر همچین چیزی نیاز داشتید بهتره سعی کنید راه دیگه ای پیدا کنید ) و اگر شما این فایل رو import کنید داخل یک ماژول دیگه خب bootstrap اجرا میشه و ما این رو نمیخوایم. پس چیکار میتونیم کنیم؟ function bootstrap() { console.log("hello"); } if (import.meta.main) { bootstrap(); } else { console.log("imported"); } اینجا هست import.meta.main به کمک ما میاد حالا اگر شما مستقیما node main.js بزنید فانکشن bootstrap اجرا میشه ولی اگر از یک فایل دیگ مثل server.js داشته باشید و این فایل رو import کنید بخش else اجرا میشه و bootstrap هیچ وقت call نمیشه.
14
981
2
1
دیتابیس های Sql مثل postgres و mysql مشکل scale ندارند. بیشتر skill issue باعث میشه scale نشن. این بلاگ پست با بلاگ پست گیت هاب که درمورد migrate کردن به mysql ورژن 8 یا 7 بود خیلی با ارزش هست
6
986
3
به تازگی نسخه جدید LTS یعنی 20.15 برای #NodeJS منتشر شده. یکی از ویژگی های کاربردی که اضافه شده مربوط به "node:test" هست. قابلیت test plan هست test('top level test', t => { t.plan(2); t.assert.ok('some relevant assertion here'); t.subtest('subtest', () => {}); }); به این صورت کار میکنه که اگر تعداد subtest ها و یا assertion ها برابر با plan نباشه تست به خطا میخوره و این موضوع در unit test خیلی میتونه کاربردی باشه به دلیل این که میتونه تست ها رو strict تر کنه. موضوع بعدی اضافه شدن یک flag جدید هست --inspect-wait یکی از مهمترین flag های #NodeJS در حقیقت خانواده flag های inspect هست. حالا سوال پیش میاد چرا؟ با کمک این فلگ ها میتونید با استفاده از ابزار های کمکی مثل chrome dev tools که یک debugger مربوط به انجین V8 داره به جنگ Bug ها و Bottleneck ها برید. برای Bottleneck یک ابزاری که اینجا در دسترس هست flamegraph هست که فارغ از زبان تو هر زبان برنامه نویسی میتونی این مدل نمودار رو ببینی ( لازمه بگم کسایی که flamegraph بلدن بخونن واقعا آدم های قابل احترامی هستن ). یکی دیگه از بزرگترین و مهمترین ابزار هایی که کمک میکنه و میتونه ساعت ها زندگیتون رو نجات بده Heap Profiler هست. کابوس هر برنامه نویس #NodeJS قطعا Memory leak هست و پیدا کردنش خیلی سخته. اما اگر از Heap Profiler درست استفاده بشه خیلی سریع میشه Memory leak ها رو پیدا کرد. چندماه هست دوست دارم درمورد inspect عمیق بشیم ولی متاسفانه فرصتش هیچ وقت برام پیش نیومده. ولی قطعا یک روز این موضوع رو عمیق میشیم. #Update
9
987
5
یکی دیگ از api های کاربردی node:perf_hooks استفاده از فانکش mark هست. این فانکشن تقریبا کاربردی شبیه به فانکشن .now داره که در پست قبلی مربوط به این موضوع توضیح داده بودم ولی یکم دست ادم رو برای log گرفتن و داشتن metadata های مختلف باز میزاره. به عنوان مثال به این کد دقت کنید. import { performance } from "perf_hooks"; import { setTimeout } from "timers/promises"; function myLogic() { // Complex logic return setTimeout(3000, "Hello NodeMaster"); } const perf1 = performance.mark("start_perf_check"); await myLogic(); const perf2 = performance.mark("end_perf_check"); console.log(perf1); console.log(perf2); به عنوان مثال یک فانکشن داریم که داره یک کار خیلی پیچیده انجام میده و این فانکش زمان بر هست استفاد از .now ممکنه جالب نباشه چون در code base های بزرگ trace کردن یکم چالش میشه. این api ها یجورایی پشت پرده ابزار هایی مثل elastic apm یا sentry هستن ولی دونستن این api های خام میتونه بهتون دید خوبی بده هرچند به صورت روزمره استفاده نکنید. در ادامه با استفاده از فانکشن mark اومدم یدونه مارک مشخص کردم که در نهایت نتیجه یک instance از PerformanceMark هست که همچین خروجی رو هم میبینیم بعد از log ها. PerformanceMark { name: 'start_perf_check', entryType: 'mark', startTime: 25.279009, duration: 0, detail: null } PerformanceMark { name: 'end_perf_check', entryType: 'mark', startTime: 3027.833827, duration: 0, detail: null } در اینجا ما name رو میبینیم که اسم mark ما هست و نیازی به توضیح نداره. در حقیقت startTime هم دقیقا لحظه ای هست که اون mark رو ما call کردیم. از لحظه اجرا برنامه تا mark اول 25ms طول کشیده و بعد از 3 ثانیه mark دوم کال میشه که در نتیجه startTime دوم رو 3027ms میبینیم. اینجا یک نکته وجود داره که حدود 3ms از 3 ثانیه بیشتر شده که این خودش نشونه اتفاقات دیگ در runtime باشه و البته موضوع مهم تر این که تضمینی وجود نداره که async job شما دقیقا در تایمی که تعریف کردیم resolve بشه. نکته بعدی این که mark به عنوان arg دوم یک object میگیره که شما میتونید توضیحات بیشتری اضافه کنید و البته مقدار startTime هم دستکاری کنید که پیشنهاد میکنم این کار نکنید مگر دقیقا میدونید دارید چیکار میکنید. const metaData = { func: myLogic.name }; const perf1 = performance.mark("start_perf_check", { detail: metaData, }); await myLogic(); const perf2 = performance.mark("end_perf_check", { detail: metaData }); حالا شما اگر این کد رو اجرا کنید اینبار detail دیگه null نیست و metaData obj رو ما میبینیم در لاگ. طبق گفته داکیومنت در هنگام استفاده از mark همیشه و همیشه مقدار duration برابر با صفر هست و در حقیقت PerformanceMark یک subclass از performanceEntry هست که در آینده بیشتر باهاش آشنا خواهیم شد. نکته بعدی این که مقدار entryType هم همیشه در این سناریو برابر با mark هست. پست قبل مربوط به این موضوع : https://t.me/NodeMaster/197 #Tip #NodeJS
4
989
1
سلام و درود دوستان امیدوارم حالتون خوب باشه. یک نکته ای که همیشه در پروژه ها میبینم چه در پروژه های Front و چه در پروژه های Backend وقتی با یک HTTP Request کار میکنیم اکثرا URL ها رو به صورت Hardcode میبینیم و اگر پارامتری هم نیاز داشته باشه در نهایت با استفاده از #JavaScript Template Literal کارمون رو پیش میبریم. به صورت کلی استفاده کردن از Template Literal هیچ مشکلی نداره و کارمون راه میندازه ولی گاهی اوقات ممکنه کمی برامون دردسر ایجاد کنه. برای درک این موضوع به مثال زیر توجه کنید. import process from "node:process"; const BASE_URL = process.env.BASE_URL; const url = `${BASE_URL}/posts/1`; fetch(url); در اینجا همه چی اوکی کار میکنه مشکلی نیست ولی یک نکته که باید توجه کنیم این هست که حتما BASE_URL ما "/" اضافه نداشته باشد. https://jsonplaceholder.typicode.com/ ❌ https://jsonplaceholder.typicode.com ✅ به صورت کلی مسئله خیلی بزرگی نیست ولی همین نکته کوچیک داخل code base که بهش آشنایی ندارید ممکنه ساعت ها ازتون زمان بگیره تا پیداش کنیم. خب حالا سوال پیش میاد که راه حل برای این موضوع چی هست؟ برای حل این موضوع میتونید از URL Web API استفاده کنید. به عنوان مثال اگر کد بالا را بخواهیم Refactor کنیم به این صورت خیلی کارمون تمیز تر و راحت تر میشه و دیگه همچین چیزی رو نمیبینیم. import process from "node:process"; import { URL } from "node:url"; const url = new URL(process.env.BASE_URL); const path = "/posts/1"; url.pathname = path; fetch(url.href); باتوجه به این که داریم از Web API استفاده میکنیم داخل تمامی Runtime ها به راحتی میتونیم از این API استفاده کنیم و همشون هم به همین شکل کار میکنن. حالا گاهی اوقات میخوایم querystring مثل زیر داشته باشیم /post?userId=1&tag=nodejs دوباره استفاده از Template literal هیچ ایرادی نداره کارمون راه میندازه ولی اگر بخواهیم این رو هم تمیز تر کنیم که در آینده کارمون راحت تر باشه و کد تمیز تری داشته باشیم چطور؟ برای این کار هم میتونیم از سه روش کارمون رو پیش ببریم 1. استفاده از node:querystring که این module فقط استاندارد #NodeJS هست. 2. استفاده از URLSearchParams Web API که باتوجه به این که Web API هست قطعا همه جا پشتیبانی میشه. 3. استفاده از راه حل دوم به صورت غیر مستقیم با استفاده از searchParams property مربوط به URL. حالا اگر بخواهیم مثال بالا رو Refactor کنیم و همچین چیزی رو اضاف کنیم به این صورت عمل میکنیم. import process from "node:process"; import { URL } from "node:url"; import querystring from "node:querystring"; const url = new URL(process.env.BASE_URL); const query = { userId: 1, tag: "NodeMaster" }; // #1 Using querystring module from NodeJS const path = "/posts"; url.pathname = path; url.search = querystring.stringify(query); // #2 Using URLSearchParams url.pathname = "/posts"; url.search = new URLSearchParams(query).toString(); // #3 Using searchParams property of URL instance url.pathname = "/posts"; url.searchParams.append("userId", "1"); url.searchParams.append("tag", "NodeMaster"); // fetch(url.href); در نگاه اول ممکنه خیلی نکته بزرگی به نظر نیاد ولی داخل code base های بزرگ که با کلی API 3rd party کار میکنید میتونه فرشته نجات باشه.
17
996
11
7
https://www.linkedin.com/posts/sheydasafiallah_aepaezaedaesabraefaesaepahyahy-aeuaepaeqahyaeuaeuaep-activity-7260940701058666496-OdR9?utm_source=share&utm_medium=member_desktop #Job
1K
2
13
برای #NodeJS آپدیت 20.14 LTS منتشر شد. ویژگی جدید خاصی به این آپدیت اضافه نشده و بیشتر باگ فیکس بوده. https://nodejs.org/en/blog/release/v20.14.0
3
1K
2
2
خب چند روز پیش این پست رو گذاشتم و گفتم این موضوع یک موضوع خیلی پایه ای مربوط به CS داخلش هست که امکان نداره کتاب درمورد زبان هایی مثل C یا سیستم عامل بخونید و به این کلمه اشاره نشه. این کلمه هست Endianness حالا سوال پیش میاد ربط این دستان با این عکس چیه. درمورد داستان سفر های گالیور هست که در دنیا Lilliputian یک مذهبی وجود داشت که تخم مرغ رو باید از قسمت کوچیک ترش بشکنی و به اینا میگن little endian. یکسری هم ظاهرا ساز مخالف که باید تخم مرغ رو از سمت بزرگش بشکنی که میشه big endian و ظاهرا در این سرزمین درگیری های زیادی هم بخاطر این که چطور تخم مرغ رو باید شکست بوده. حالا چه ربطی به کامپیوتر داره؟ شما این عدد رو در نظر بگیرید که معادل HEX این رو داخل عکس میبینید. 168,496,141 = 0A0B0C0D در ریاضی دوم دبستان وقتی یکان دهگان صدگان یاد گرفتیم به این درک رسیدیم که سمت چپ ترین عدد بیشترین وزن رو داره که به این صورت میتونیم عدد بالا رو نشون بدیم. 100,000,000 + 60,000,000 + 8,000,000 + 400,000 + 90,000 + 6,000 + 100 + 40 + 1 حالا اگر تبدیل مبنا ها رو بلد باشید اگر دیتا bin رو بخواید تبدیل به decimal کنید میدونید که bit ها هرکدوم وزن دارند. حالا یک بحثی اینجا هست که اگر بخوایم یک دیتایی رو در یک مجموعه متوالی از حافظه بخوایم ذخیره کنیم اون قسمتی که بیشترین وزن رو دارد آیا باید در اولین خونه حافظه قرار بدیم یا در آخرین خونه حافظه مربوط به این بخش. خب اینجا معماری های مختلف CPU مثل X86, ARM, RISC-V جنگ تخم مرغی خودشون دارن ( دقیق یادم نمیاد کدوم چه شکل هست میتونید خودتون برید سرچ کنید ) بعضیا دوست دارن که اون Byte که بیشترین وزن رو داره در اولین خانه از حافظه ذخیره بشه. این میشه Big endian در عکس هم که میبینید مقدار 0A که دراین سناریو بیشترین وزن رو داره در خانه A که اولین خانه RAM هست در این سناریو ذخیره شده. بعضیا هم میگن که باید اون Byte که بیشترین وزن رو داره در آخرین خانه از حافظه باید ذخیره بشه و اولین خانه از حافظه باید کمترین وزن رو داشته باشه. این میشه Little endian که در عکس میبینید مقدار 0A در این سناریو در آخرین خانه از حافظه یعنی A+3 ذخیره شده که بیشترین وزن رو داره و در خانه اول یعنی A مقدار 0D ذخیره شده. #CS
8
1K
1
اگر تا حالا فکر کردین که چطور فریمورک ها رو برای ما developer های عادی توسعه میدن جواب شما یک magic هست به اسم #Metaprogramming . این کار مثل برنامه نویسی معمولی که ما انجام میدیم تکنیک های مختلف داره که یکی از اونها رو در این پست باهم برسی کردیم. https://t.me/NodeMaster/115 البته لازم به ذکر هست یکسری Pattern به صورت کلی وجود داره که بین زبان های مختلف مشترک هست و به نوعی پیاده سازی های مختلف ازش دیده میشه و البته یکسری زبان ها هم یکسری تکنیک های مخصوص به خودشون رو هم دارن که اون ها رو خاص تر میکنه. حالا یکی از این جادو های کاربردی #Metaprogramming این هست که اگر یک Instance از یک Object داریم که یک Parrent Class داره چطور فقط و فقط متوجه بشیم که چه Attr هایی مخصوص به اون Child Class هست و Attr های Parrent رو نادیده بگیریم. و جواب این سوال خیلی سادس : const myPrototype = { x: 1, y: 2 }; // Parrent const myObj /* Child */ = Object.create(myPrototype); myObj.name = "point"; // Instance Prop console.log(Object.getOwnPropertyNames(myObj)); // [ 'name' ] console.log(Reflect.ownKeys(myObj)); // [ 'name' ] console.log("x in myObj :", "x" in myObj); در #JavaScript با استفاده از Object.getOwnPropertyNames و Reflect.ownKeys(myObj) میتونیم متوجه بشیم که کدام Atter ها مربوط به Instnace ما یعنی myObj هستند. به این خاطر هست که Atter های Parrent یعنی x و y رو کامل نادیده گرفته میشه و فقط در name رو ما به عنوان Attr میبینم که مستقیما روی Child Instance ما تعریف شده و نه روی Parrent. شاید این مثال یکم پیچیده باشه بخاطر ماهیت Object ها در #JavaScript هست. همین رو اگر بخوایم در #Python برسی کنیم شاید یکم قابل درک تر باشه و البته مثال های دیگ هم در #JavaScript میشه زد ولی خب به نظرم بهتره بزاریم برای کنجکاوی خودتون. class Parrent: def __init__(self) -> None: self.x = 1 self.y = 2 class Child(Parrent): def __init__(self) -> None: super().__init__() self.name = "point" myObj = Child() parrentAttrs = set(dir(Parrent())) childAtters = set(dir(Child())) print(childAtters.difference(parrentAttrs)) یک نکته خیلی جذاب کلا خارج از بحث که به نظرم ارزش توجه کردن داره استفاده از set برای رسیدن به نتیجه ای شبیه به مثال #JavaScript هست. و اینجا به عنوان مثال مستقیم یکی از کاربرد های Set Object و Set theory رو مستقیم و خیلی کوچیک میبینید. نکته ای که خیلی مهم باید توجه بشه این هست که بین تکنیک استفاده از ownKeys و getOwnPropertyNames تفاوت هایی وجود داره که اگر استقبال بشه عمیق تر وارد این موضوع میشیم. #Tip
8
1K
7
3

در حال مطالعه داکیومنت Tron هستم برای کار با Smart Contract ها و ... که یک نکته خیلی ریز در اصل یک کلمه خیلی توجهه من رو جلب کرد. به عکس بالا دقت کنید، مخصوصا به بخش highlight شده، مخصوصا به کلمه "compatible". این کلمه خیلی کلمه مهمی هست. حالا بخوام یکم Context بدم درمورد موضوع این هست که Smart Contract های ERC-20 که روی شبکه ETH هستن باید کدشون کاملا سازگار باشه با TRC-20 که روی شبکه Tron هست. و اینجا اگر دقت کنیم دوباره میرسیم به این جمله معروف. "program to interfaces, not implementations" چند ماه پیش درمورد دلیل این که چرا درک این جمله اینقدر مهمه صحبت کردم و پست هایی هم داشتیم. حالا داستان "compatible" چیه ؟ اگر شما برید کد Smart Contract مربوط به USDT رو چک کنید متوجه کلمه های ERC میشید که این مربوط به شبکه ETH هست ولی روی شبکه Tron. خیلی ساده بخوام بگم ما مفهوم این جمله رو داریم در Scale خیلی بزرگ میبینیم و سرنخ این موضوع در حد یک کلمه همینقدر ریز هست. این هم لینک اون پست. دوستان واقعا زندگی برنامه نویسی شما بعد از درک این مفهوم به دو بخش تقصیم میشه. قبل و بعد از درک این موضوع. https://t.me/NodeMaster/137
16
1K
1
نسخه 20.16 LTS مربوط به #NodeJS خیلی وقته اومده و خب چون مدتی فعال نبودیم. از دست ما در رفته نگاهی بهش بندازیم. یک فانکشن کمکی به این نسخه اضافه شده و از این زاویه جالب هست که یک حرکت eco system رو نشون میده که برای ما developer ها در در طولانی مدت میتونه خوب باشه. این که در آینده کدهای بیشتری ببینیم که به runtime خاصی وابسته نباشن و فریم ورک های جدید تر روی هر runtime به صورت native اجرا بشه. فانکشن کمکی جدید process.getBuiltinModule این فانکشن به ما کمک میکنه که در runtime هر ماژولی رو از std مربوط به #NodeJS به راحتی import کنیم. حالا سوال پیش میاد که چرا از خود ES import استفاده نمیکنیم. به این دلیل که اگر یک کد داشته باشیم که به #Deno وابستگی داره حالا اگر بخواهیم اون کد رو با #NodeJS ران کنیم بره و از std مربوط به Node استفاده کنه و نه Deno. بزارید با مثال این رو ببینیم. نمونه ای خوب و ساده از Factory pattern و Polymorphism هم میشه دید. اگر تازه کارتر هستید و در حال یادگیری به این مثال بیشتر دقت کنید خیلی بهتون کمک خواهد کرد. class DenoReader { constructor() { this.decoder = new TextDecoder(); } readFile(fileName) { const byteArray = Deno.readFileSync(fileName); const result = this.decoder.decode(byteArray); return result; } } class NodeReader { constructor() { this.fs = globalThis.process.getBuiltinModule("fs"); } readFile(fileName) { const result = this.fs.readFileSync(fileName).toString("utf-8"); return result; } } function getReader() { switch (true) { case globalThis.Deno !== undefined: return new DenoReader(); case globalThis.process.getBuiltinModule !== undefined: return new NodeReader(); default: throw new Error("No Reader available"); } } const nodeReader = getReader(); const nodeResult = nodeReader.readFile("my-text.txt"); console.log(nodeResult); هدف خوندن یک فایل از روی disk هست و البته که این کد برای runtime های #Deno و #NodeJS از Native API مربوط به هر runtime استفاده کنه. باتوجه به این که این runtime ها هرکدوم دنیای خودشون رو دارن و API های خاص خودشون. اول باید یک API مشترک برای این دوتا بسازیم که بتونیم به هدفمون برسیم. اینجا Factory pattern به کمک ما میاد که بهمون اجازه میده با استفاده از type switch تصمیم بگیریم که روی کدام runtime هستیم و با توجه به اون runtime کلاس reader مربوط بهش رو بهمون میده و البته با استفاده از Duck typing در #JavaScript یا با استفاده از interface ها در #TypeScript یک interface یکسان برای خواندن فایل با دو implemetion متفاوت باید ایجاد کنیم که در بالا معادل NodeReader و DenoReader هست که readFile میشه interface یکسان بین این دو. نکته قابل توجه این که چون اینجا مشخص نیست کدوم runtime رو قراره استفاده کنیم، استفاده از top-level import به صورت کلی کنسل هست به این دلیل که اگر کد زیر بزاریم و برنامه با Deno ران کنیم کلا هدفمون میره تو دیوار. import fs from "node:fs"; یک سوال دیگ که پیش میاد دقیقا همین ویژگی رو ما میتونیم با استفاده از dynamic import داشته باشیم چرا از اون استفاده نکنیم؟ در جواب این موضوع مشکل خیلی خاصی به وجود نمیاد. مزیت این روش نسبت به dynamic import این هست که این روش به صورت sync فرایند import رو انجام میده درصورتی که حاصل dynamic imprort یک Promise هست که اگر ESM باشید با top-level await میتونید تمیز حلش کنید. اما اگر روی CJS باشید کثیف کاری خواهید داشت در نتیجه در این سناریو این روش جدید منطقی تر به نظر میرسه. قبلا هم درمورد Duck typing مفصل صحبت کرده بودیم که اینجا میتونید ببینید اگر دوست داشتید. https://t.me/NodeMaster/136
11
1K
5
این اولین بلاگ پست یکی از نزدیک ترین دوستان من هست که داخل AMD منتشر شده و درمورد استفاده از #k8s برای نیاز های AI برای کارت گرافیک ها AMD هست. دوست داشتید نگاهی بندازید مخصوصا اگر #K8S آشنایی دارید. https://rocm.blogs.amd.com/software-tools-optimization/gpu-operator-partitioning/README.html
11
1K
2
درود و وقت بخیر. مدتی فعالیت نداشتم و امروز دوباره برگشتم و امیدوارم هرجا هستید حالتون خوب باشه. در حال حاظر به صورت Full time دارم مطالعه میکنم قطعا پست های جالب تر و عمیق تری نسبت به قبل خواهیم داشت. امروز برای دست گرمی با معرفی یک ابزار شروع میکنیم. اگر برای سرویستون تست مینویسید و تست های شما وابستگی به دیتابیس داره برای سرعت معمولا سعی میشه که تست ها با یک دیتابیس in-memory اجرا بشه که وابستگی بیرون نداشته باشه و دردسر کمتری هم این روش داره. حالا مشکلی که اینجا وجود داشت این که اگر پروژه شما به #MongoDB وابستگی داشته باشه در این راه برای استفاده از پکیج مربوط به In memory در حالت هایی دردسر زیادی داره که استفاده از روش های پایین خیلی منطقی تره. روش هایی که در این حالت میشد استفاده کرد به این صورت بودن: - استفاده یک دیتابیس جدا و کاملا ایزوله - استفاده از Service ها در CI/CD pipeline مثل github and gitlab services ( در صورت نبود دیتابیس in memory این روش خیلی بهتری هست ) https://docs.github.com/en/actions/use-cases-and-examples/using-containerized-services/about-service-containers https://docs.gitlab.com/ee/ci/services/ برای دیتابیس های SQL هم معمولا از #Sqlite نسخه In-memory رو به عنوان engine در هنگام تست استفاده میکنن ولی به این نکته باید توجه داشت که #Sqlite مثل هر #SQL دیگ تفاوت هایی با بقیه دارد و اگر همون تست ها رو بخواید با دیتابیس دیگ مثل #Postgres و #MySQL اجرا کنید ممکنه به خطا بخورید که این هم بخاطر تفاوت ها هست. مخصوصا اگر در تست هاتون به Primary key وابستگی داشته باشید که قطعا خیلی زیاد پیش میاد. ولی درکل هندل کردنشون به طوری که روی همشون کار کنه کار سختی نیست و با ریفکتور کوچیک بیشتر مواقع این موضوع حل میشه. نمونه کد برای اجرا کردن #Sqlite با #NodeJS پکیج استاندارد جدیدی که اخیرا اضافه شده. import { DatabaseSync } from 'node:sqlite'; const database = new DatabaseSync(':memory:'); البته شما باید باتوجه به ORM که استفاده میکنید کانفیگ رو انجام بدید. برای Redis هم که Package مربوط به redis in-memory هست میتونید نصب کنید و استفاده کنید. و حالا میرسیم برای #MongoDB دردسر ساز که این پکیج کارتون رو راه میندازه. نکته ای که وجود داره این که شما اگر بخواید با استفاده از in memory mongo پروژه خودتون تست کنید اگر هر نسخه از #NodeJS کانتینر برای تست خودتون استفاده کنید کار نمیکنه که جزیاتش رو میتونید داخل داکیومنتش ببینید و البته در این حالت ترجیح میدم از سرویس services مربوط به gitlab یا github استفاده کنم. https://github.com/typegoose/mongodb-memory-server
8
1K
4
49
به تمامی دوستان چه تازه کار و چه کسانی که سال ها تجربه دارند پیشنهاد میکنم حتما مفاهیم 12factor رو مطالعه کنند. خیلی از قدیمی تر ها این مفاهیم رو با سال ها کسب تجربه و به سختی به دست آوردن و همچین منبعی که به صورت خیلی خلاصه این ها رو به تمیز ترین شکل ممکن توضیح میده واقعا خیلی با ارزش هست. https://12factor.net/ #Resource
15
1K
45
یکی از ویژگی های جدیدی و کاربردی که در #ES2024 اضافه شده و هم برای بچه های #Frontend و هم #Backend میتونه مفید باشه. یکی از pattern های معروف برای ایجاد یک async function در #JavaScript به این صورت هست. function job() { return new Promise((resolve, reject) => resolve(2)); } معمولا از این ویژگی وقتی استفاده میشه که قصد داریم یک wrapper برای یک CPS Style Async Function بنویسیم. قبلا در مورد این که CPS Style چیست و چرا مفصل صحبت کردیم و میتونید از این لینک مطالعه کنید. https://t.me/NodeMaster/19 حالا با این API جدید میتونیم کد بالا به این صورت refactor کنیم function job() { const { promise, reject, resolve } = Promise.withResolvers(); resolve(2); return promise; } با استفاده از static method جدیدی که به Promise اضافه شده یعنی Promise.withResolvers میتونیم از شر constructor خلاص بشیم. ( یجورایی میشه گفت factory pattern حساب میشه ) یک موضوع شاید براتون سوال پیش که چرا گفتم از شر constructor خلاص بشیم. آیا مشکلی داره؟ جواب طبق سایر جواب ها برنامه نویسی میتونیم بگیم بستگی داره. ولی من حس میکنم با توجه به تغییراتی که من میبینیم به مفهوم Aggregation در OOP خیلی احترام بیشتری داره گذاشته میشه. این آپدیت خیلی جدیده و در حال حاظر در #NodeJS ورژن 22 هستش. البته دوباره این رو باید بگم که #Deno پرچم داری کرده و از ورژن 1.38 این ویژگی رو زودتر اضافه کرده. #Tip
9
1.1K
5
Node.js Backend Developer 📍 مکان: تهران – با امکان دورکاری کامل یا هیبریدی 👨💻 نوع همکاری: تماموقت یا پارهوقت (ساعت کاری منعطف، مبتنی بر خروجی) درباره ما ما یک تیم تحقیق و توسعهی پویا هستیم که روی ساخت محصولات دیجیتال نوآورانه با محوریت هوش مصنوعی، دادهکاوی و سرویسهای کاربردی وب کار میکنیم. تمرکز ما روی طراحی و پیادهسازی معماریهای تمیز، مقیاسپذیر و انعطافپذیر برای پروژههاییست که کاربران واقعی و چالشهای فنی جدی دارند. در حال حاضر به دنبال یک توسعهدهندهی بکاند با Node.js هستیم که عاشق حل مسئله و طراحی سیستمهای پایدار باشه و بتونه در ساخت سرویسهای مقیاسپذیر و حرفهای نقش کلیدی ایفا کنه. مسئولیتها طراحی و توسعهی سرویسهای بکاند با استفاده از Node.js (ترجیحاً با Nest.js یا Express.js) طراحی و پیادهسازی APIها (RESTful / GraphQL) با رعایت اصول امنیتی و بهینهسازی اتصال به دیتابیسهای MongoDB و PostgreSQL و طراحی مدل دادهی کارآمد پیادهسازی صفهای پردازش با Kafka یا RabbitMQ استفاده از Redis برای کشینگ و بهبود عملکرد سیستم مشارکت در طراحی معماری سیستمها بر اساس Clean Architecture و Design Patterns همکاری در Code Review و بهبود کیفیت کد تیم مستندسازی مؤثر برای ماژولها و سرویسها مهارتها و تجربهها تسلط بالا به Node.js و یکی از فریمورکهای محبوب (Nest.js یا Express.js) تجربه کار عملی با MongoDB و PostgreSQL آشنایی با ابزارهای Messaging Queue مثل Kafka یا RabbitMQ تجربهی استفاده از Redis برای کش و مدیریت Session آشنایی با مفاهیم Microservices و معماریهای رویدادمحور (Event-driven) تسلط به Git و آشنایی با ابزارهای مدیریت پروژه (Jira یا مشابه) توانایی تستنویسی (Unit/Integration) درک مفاهیم امنیتی وب و استانداردهای OWASP آشنایی با CI/CD و مفاهیم DevOps امتیاز محسوب میشود چرا اینجا جذابه؟ تیم حرفهای ولی صمیمی داریم محیط کاری آزمایشی + تحقیقاتی، مناسب عاشقان یادگیری امکان دورکاری کامل یا حضور در دفتر (اگر تهران باشی) ساعت کاری شناور؛ تمرکز ما روی نتیجهست، نه زمان درگیر پروژهای میشی که کاربر واقعی، مقیاسپذیری و چالشهای معماری جدی داره اگر این موقعیت برات جالبه، لطفاً برامون بفرست: رزومه (حتی اگر خیلی رسمی نیست) لینک گیتهاب یا چندتا از پروژههای قبلیت حقوق پیشنهادی (اختیاری) مدت زمانی که میتونی در هفته همکاری داشته باشی @amirjaha_n [email protected]
1.1K
12
چند روزی هست که #Deno نسخه 1.46 منتشر شده. از نکات جالبی که اضافه شده deno serve --parallel این flag یکجورایی شبیه به cluster در #NodeJS عمل میکنه. البته اگر درموردش مطالعه کنید تفاوت هایی هست. - آپدیت بعدی مربوط به deno fmt هست که فرمت های مختلف مثل html css ,scss, yml و ... رو هم انجام میده. - یکی از تغیرات مهم دیگ پایدار شدن std مربوط به #Deno هست. نکته جالب در این مورد این هست که این std ها رو شما میتونید روی پروژه های #NodeJS خودتون هم استفاده کنید. و از همه مهتر Deno 2 خیلی نزدیک هست و این آپدیت یعنی نسخه 1.46 آخرین آپدیت نسخه 1.X میباشد. https://deno.com/blog/v1.46
3
1.1K
2
جا داره تشکر کنم از همه دوستان. چنل 800 نفر شد و گروه هم 300 نفر به تازگی شدیم. دوستان جدید خیلی خوش اومدین❤️ دوستان قدیمی تر مرسی که همراه من بودین تا اینجا❤️. دوستان جدید تر خدمت شما بگم که اگر دوست داشتید ما یک گروه داریم که درمورد مفاهیم برنامه نویسی صحبت میکنیم و خوشحال میشیم کنارمون باشید. @NodeMasterGP و اگر نیاز به کمک و راهنمایی دارید اگر دوست داشتید پیوی من میتونید پیام بدین و واقعا خوشحال میشم اگر بتونم کمکی کنم. @napoleon_n1 و این که از همتون واقعا ممنونم که به من لطف دارین و باعث پیشرفت من شدین❤️ داداش کوچیک شما ایمان هستم👍🔥
22
1.1K
11
باورم نمیشه مفهوم به این عمیقی در CS این روزا ها میشه بهش نگاه سیاسی داشت. این توییتم درمورد halting problem توضیح دادم. خیلی زیاد یادم نیست در این مورد و خیلی خلاصه و ساده سعی کردم توضیح بدم که هر خواننده ای بتونه بخونه. ولی در کل برای شما میتونه یک سرنخی باشه برای عمیق تر شدن در این موضوع. https://x.com/imanhpr_media/status/1808831653323608501 #CS #Tip
3
1.1K
4
1
سلام به همگی دوستان که جدید اومدن خیلی خیلی خوش اومدین. قدیمی ها دمتون گرم مرسی که همیشه همراه من بودین. لینک گروه بچه ها ما اینجا هست خوشحال میشم اگر دوست داشتید به کامینیوتی کوچیک ما جوین بشید. https://t.me/NodeMasterGP
9
1.1K
درود رفقا امیدوارم حالتون خوب باشه. بلاخره تلسم رو شکوندم بعد از چند ماه این ویدیو رو گرفتم. در این ویدیو باهم یاد میگیرم که چطور از AsyncLocalStorage استفاده کنیم در #NodeJS البته قبل از هرچیزی میریم نگاهی به react context در #React میکنیم که از بچه های #FrontEnd یاد بگیرم چطور همچین مسائلی رو که AsyncLocalStorage به ما کمک میکنه حل کنیم رو با react context حل میکنن. https://youtu.be/B_s401HuZAU
18
1.1K
5
7
فرض کنید یک وب سایت فروشگاهی دارید و در حال توسعه API هستید که میخواید وضعیت سفارش ها رو در پنل ادمین نمایش بدین. کارفرما از شما میخواد که Status های درحال انتظار در اول قرار بگیره و بقیه هم بعد از اون. در این حالت با این Query کارتون رو میتونید راه بندازید. ORDER BY CASE WHEN Status = 'WAIT' THEN 0 ELSE 1 END, Date DESC #Tip #SQL
23
1.1K
5
22
یک Pattern وجود داره که خیلی درموردش صحبت نمیشه در اکوسیستم #JavaScript چه پروژه های #FrontEnd و چه #Backend که با #NodeJS و بقیه runtime ها توسعه داده شده باشن. این پترن خیلی ساده هست. استفاده نکردن ( یا حداقل استفاده ) از Anonymous function ها میباشد. حالا سوال پیش میاد چرا از این پترن باید استفاده کنیم؟ وقتی دارید برنامه توسعه میدین و به نوعی چه توسط خودتون یا Framework که استفاده میکنید با فرایند IOC درگیر هستید مثل #React یا حتی #Express و ... اگر سایز پروژه بزرگ باشه برای پیدا کردن Bug ها به هیچ عنوان تکنیک console.log راه بهینه ای نیست. و معمولا از ابزار ها و تکنیک های مختلف در کنار هم استفاده میشن تا این فرایند راحت تر باشه. در کنار این مفاهیم لاگ کردن Error ها و stack trace مربوط بهشون خیلی مهم هست و خیلی کمک میکنه تا scope مربوط به به باگ رو کوچک تر کنیم و سریعتر بتونیم باگ رو پیدا کنیم. با استفاده زیاد از Anonymous function ها که معمولا بیشتر در هنگام arg برای پاس دادن به عنوان callback استفاده میشن، stack trace شکل خوبی نخواهد داشت و اگر زیاد استفاده بشه حتی stack trace میتونه کاملا بی مصرف بشه و با این کار یکی از عناصر خیلی مهم برای debug کردن رو از دست میدیم. به مثال زیر توجه کنید. function iocContainer(cb) { cb() } iocContainer(() => { throw new Error("ugly stack trace") }) at /home/imanhpr/codes/main.js:6:28 at iocContainer (/home/imanhpr/codes/main.js:2:5) at Object.<anonymous> (/home/imanhpr/codes/main.js:6:1) اینجا سایز پروژه کوچک هست و راحت میشه Error رو پیدا کرد چون جزیات زیادی در stack وجود نداره و کد framework هم در نظر گرفته نشده. اما توجه داشته باشید که اون خط آخر یعنی Object.anonymous در شرایط فشار باگ روی production خیلی میتونه ترسناک باشه.یک نکته که حتی میتونه وحشتناک تر کنه داستان رو پروژه #TypeScript بدون source map و اگر به این ترکیب esbuild هم اضافه بشه جای صحبتی اصلا باقی نمیمونه. حالا با یک مثال واقعی تر و خیلی ساده این موضوع رو برسی میکنیم const express = require("express") const app = express() app.get("/", (req, res) => { throw new Error("ugly error") }) app.listen(3000) Error: ugly error at /home/imanhpr/codes/main.js:6:11 at Layer.handle [as handle_request] (/home/imanhpr/codes/node_modules/express/lib/router/layer.js:95:5) at next (/home/imanhpr/codes/node_modules/express/lib/router/route.js:149:13) at Route.dispatch (/home/imanhpr/codes/node_modules/express/lib/router/route.js:119:3) at Layer.handle [as handle_request] (/home/imanhpr/codes/node_modules/express/lib/router/layer.js:95:5) at /home/imanhpr/codes/node_modules/express/lib/router/index.js:284:15 at Function.process_params (/home/imanhpr/codes/node_modules/express/lib/router/index.js:346:12) at next (/home/imanhpr/codes/node_modules/express/lib/router/index.js:280:10) at expressInit (/home/imanhpr/codes/node_modules/express/lib/middleware/init.js:40:5) at Layer.handle [as handle_request] (/home/imanhpr/codes/node_modules/express/lib/router/layer.js:95:5) این مثال کیلومتر ها با پیچدگی پروژه های production فاصله داره اما همین کد ساده نشون میده چقدر توجه به این نکته میتونه ساعت ها از وقت شما نجات بده و کار کم استرس تری هم تجربه کنید. مشکل دقیقا خط اول stack trace هست که هیچی ازش وجود نداره ( در این مثال خوش شانسیم که خطی که این اتفاق افتاده دقیقا اشاره داره به همون callback ما ولی همیشه اینطور نیست ) برای داشتن زندگی شیرین تر کافیه کمتر از Anonymous function ها چه به شکل arrow و چه با function keyword استفاده کنید. و برای function ها نام مناسب انتخاب کنید. مثل سناریو پایین که rootHandler رو داریم. app.get("/", function rootHandler(req, res) { throw new Error("ugly error") }) // OR const rootHandler = (req, res) => { throw new Error("ugly error") } app.get("/", rootHandler) Error: ugly error at rootHandler (/home/imanhpr/codes/main.js:6:11) at Layer.handle [as handle_request] (/home/imanhpr/codes/node_modules/express/lib/router/layer.js:95:5) حالا چند نکته باید در نظر بگیرید. - تفاوت arrow function و function keyword رو بدونید گاهی ممکنه دردسر ساز بشه. - اگر از #TypeScript استفاده میکنید از اهمیت source map هرگز غافل نشید. #Tip
15
1.1K
5
یک خورده دارم #React مرور میکنم برای پروژه شخصی. یک موضوعی که به ذهنم اومد این هست که چطور موقع هندل کردن event ها با handler function ها چطور stack trace تمیزی داشته باشیم. در این پست درمورد این موضوع و این که چطور stack trace تمیزی داشته باشیم با مثال #Express روی #NodeJS صحبت کردیم. https://t.me/NodeMaster/228 در این پست هم راجع به Reflection اشاره ای کردیم. https://t.me/NodeMaster/121 حالا شما component زیر که خیلی ساده هست رو در نظر بگیرید function SimpleComp() { function clickHandler() { console.log("handler fn :", clickHandler.name); } return <button onClick={clickHandler}>click here!</button>; } بزارید همین اول بگم این نکته شاید خیلی زیاده روی باشه و نیاز نباشه ولی خب میتونه برای درک بهتر Reflection درنظر گرفتش. تا اینجا باتوجه به چیزایی که میدونم stack trace خوبی خواهیم داشت به دلیل این که clickHandler اسم داره. سناریویی رو در نظر بگیرید که دارید روی یک سری دیتا loop میزنید و برای هر Entity که دارید یک clickHandler ایجاد میکنید. سوال پیش میاد وقتی روی یکی از این function ها کلیک و call میشه چطور بدونیم کدوم call شده دقیق؟ ۱. راه حل ساده تر و همیشه جواب log کردن هست. ۲. راه حل پیچیده تر کمک از Reflection و تغییر اسم function در runtime. دوستان لزوما نیازی نیست از Reflection استفاده کنید. با log کردن صحیح نیازی اصلا ندارید و فقط این روش پیچدگی بیهوده اضاف میکنه و صرفا برا عمیق شدن داریم میریم جلو. function SimpleComp({ id }) { function clickHandler() { console.log("handler fn :", clickHandler.name); } Reflect.defineProperty(clickHandler, "name", { value: clickHandler.name + "_" + id, }); return <button onClick={clickHandler}>click here!</button>; } در اینجا من اومدم به اسم فانکشن Id که به عنوان prop اومده رو در runtime اضافه میکنم و خب این دقیقا معادل همچین چیزی میشه. function clickHandler_2 (){} اسم فانکشن به صورت عادی یکی از چیزایی هست که زمان compile time ( یا اینجا dev time میشه بهش گفت هرچند خیلی مرسوم نیست) مشخص میشه و خب وقتی چیزی رو در این زمان داشته باشیم dynamic کردنش نزدیک به غیرممکن هست. حالا اینجا Reflection بهمون کمک میکنه که در runtime یک چیزی که به صورت عادی دردسترس نیست رو تغییر بدیم مثل name atter برای function ها که در این مثال دارید میبینید و دقیقا این موضوع معادل کد clickHandler_2 هست با این تفاوت که در runtime ایجاد میشه و نه compile time. #Tip
11
1.1K
6
دوستان نسخه LTS جدید یعنی 22 اومد. الان میتونید پروژه ها خودتون آپدیت کنید. به زودی در یک ویدیو تمام آپدیت های اخیر رو باهم برسی خواهیم کرد. https://nodejs.org/en/blog/release/v22.11.0 #Update
11
1.1K
14
چند روزی هست #NodeJS نسخه 23 منتشر شده و بزودی 22 LTS رو میبینیم. سعی میکنم تغییرات رو باهم برسی کنیم در آینده. https://nodejs.org/en/blog/release/v23.0.0
13
1.1K
1
5
وقتی در حال توسعه با #NodeJS هستید یکی از مشکلاتی که در حال حاظر وجود داره استفاده از #TypeScript در هنگام توسعه میباشد. باتوجه به آپدیت های اخیر #NodeJS حرکت هایی جهت پشتیبانی راحت #TypeScript در #NodeJS با اضافه کردن فلگ های --experimental-transform-types و --experimental-strip-types تغییراتی داشته ولی همچنان تا Production ready بودن خیلی فاصله داره. گزینه های که میتونه بهتون در این مورد کمک کنه استفاده از ts-node و tsx هست. در یک سال گذشته شخصا از هردو در پروژه های مختلف استفاده کردم. با توجه به آزمون و خطایی که من کردم در حال حاظر tsx خیلی خیلی بهتر از ts-node هست و کارتون رو به خوبی راه میندازه. https://tsx.is/
10
1.2K
7
6
درود دوستان وقت همگی بخیر باشه. یک مدتی هست فعالیت کانال کم شده و شخصا خیلی فعالیتی ندارم. خواستم بگم. یک مدت کوتاهی میخوام استراحت کنم ولی بعد دوباره با هم ادامه خواهیم داد. امیدوارم موفق باشین❤️
36
2
1.2K
1
ظاهرا به صورت std قراره sqlite به #NodeJS اضافه بشه. خبر جالبی هست. اینجا میتونید اطلاعات بیشتر رو دنبال کنید. https://github.com/nodejs/node/pull/53752 #NodeWeekly
6
1.2K
3
32
#Work این تیم دنبال #NodeJS میگرده اگر دوست داشتید رزومه خودتون رو بفرستید. https://jobvision.ir/jobs/job-detail/770925?ReferrerJobPosition=8&row=3&pageSize=30&keyword=node&searchId=385378404706959333
1.2K
5
درود دوستان. قبلا که #python کد میزدم یک پکیج داشت به اسم isort که import ها رو خیلی تر تمیز sort میکرد. همیشه دنبال یک پکیج خوب بودم برای #typescript که همچین کاری رو انجام بده تا بلاخره دیروز یک پکیح خوب پیدا کردم که میتونید به عنوان config prettier استفاده کنید. البته package های دیگ هم هستن ولی این خیلی برای من راحت تر بود. فکر کنم eslint هم همچین چیزی داشته باشه ولی فرصت نشده تست کنم. https://www.npmjs.com/package/prettier-plugin-organize-imports
7
1.2K
12
15
یکی از ابزار هایی که وقتی با #Postgres کار میکنید و کمتر استفاده میشه ولی خیلی کاربردی هست Window function ها هستن. به صورت کلی Window function ها این قابلیت رو میدن که دسترسی داشته باشین به مجموعه row های قبل یا بعد از record که در حال حاظر در حال برسی هست. به عنوان مثال سناریویی رو در نظر بگیرد که نیاز دارید یک سطر X رو با سطر های X+N یا X-N برسی کنید ( row های قبل یا بعد ). یکی از کاربرد هایی که ممکنه براتون داشته باشه داخل کار کردن سناریو هایی است که با Timeseries دیتا ها سرکار دارید. سینتکس مربوط به استفاده از window function ها به صورت کلی به این صورت هستن. window_function(arg1, arg2,..) OVER ( [PARTITION BY partition_expression] [ORDER BY sort_expression [ASC | DESC] [NULLS {FIRST | LAST }]) - منظور از window_function در اینجا اون فانکشنی هست که میخوایم استفاده کنیم به عنوان مثال LAG function - قسمت PARTITION BY به صورت کلی شباهت هایی به Group by دارد ولی در حال حاظر کاری بهشون نداریم. - قسمت Order by هم ترتیب مقایسه Row ها رو با سطر بعد یا قبلش مشخص میکنه. دقیقا مثل Order by در حالت معمولی کار میکنه. به صورت کلی window function های مختلفی داریم ولی برای درک بهتر و این که یک مثال ساده داشته باشیم LAG function هم کاربردی هست هم ساده. فرض کنید یک table دارید که تعداد فروش محصولات رو برای هر سال دارد. "year","sales_amount" "2018","100" "2019","120" "2020","150" "2021","180" حالا سناریویی رو تصور کنید که میخواید در هر سطر برسی کنید که نسبت به سال قبل چقدر محصول بیشتر فروش داشتین؟ اینجا LAG function به داد شما میرسه SELECT year, sales_amount, sales_amount - LAG(sales_amount , 1) OVER (ORDER BY year) AS sales_diff FROM sales; در اینجا ما نیاز داریم که مقدار sales_amount سطر جاری رو از sales_amount سطر قبل که مربوط به سال قبل هست کم کنیم که تفاوت این دو رو بتونیم به دست بیاریم. حالا Lag 3 تا arg میگیره که به این ترتیب هستن - نام فیلدی که دیتا مربوط به سطر قبل یا بعدش رو لازم داریم. - مقدار offset که میتوان عدد منفی به عنوان مثل -1 هم داشت. به صورت پیش فرض عدد 1 هست - مقدار سوم که در اینجا نداریم default value هست که به صورت پیش فرض Null هست وقتی معمولا پیش میاد که در سطر اول یا اخر در هرکدوم از این سناریو ها ممکنه سطر بعدی یا قبلی وجود نداشته باشه پس در نتیجه یک مقداری باید قرار بگیره که پیش فرض Null هست حالا وقتی Query رو اجرا کنید همچین نتیجه ای میبینید. year,sales_amount,sales_diff 2018,100, 2019,120,20 2020,150,30 2021,180,30 جمع بندی: کلا Window function ها ابزار های قدرتمندی هستن که بهمون خیلی کمک میکنن Query های پیچیده ای بزنیم که ممکنه در بیزینس لاجیک های خاص مخصوصا وقتی با timeseries دیتا کار داریم انجام بدیم. موضوع بعدی این که ترکیبشون با Subquery یک ترکیب قدرتمند هست که رسما میشه Query هایی رو نوشت که در حالت عادی باتوجه به Data model که داریم ممکنه بدست آوردن اون دیتا غیرممکن باشه و قبل از هرچیزی برای رسیدن به نتیجه وقتی نیاز داریم که دیتا رو یک تغییرات بدیم و بعد از روی اون به اطلاعات برسیم; سناریو خوبی هست برای استفاده از این دو مفهوم.
19
1.2K
15
درود و وقت بخیر دوستان. امیدوارم حالتون خوب باشه. اخیر یک ویدیو دیدم درمورد این که چطور در Netflix از #Java استفاده میکنن. سوال پیش میاد چرا این ویدیو باید برای ما جالب باشه و اهمیت بدیم؟ باتوجه به این که این روزا به شدت تکنولوژی در حال پیشرفت هست و هر روز ابزارها و فریمورک های جدید رو شاهد هستیم. این حس رو به ما القا میکنه که باید سریع باشیم و این تکنولوژی های جدید رو یاد بگیریم و اگر یاد نگیریم عقب میافتیم و در بازار کار جایی نخواهیم داشت! منطقی هست باتوجه به این سرعت پیشرفت و AI این حس FOMO خیلی بیشتر شده به خصوص برای دوستانی که تازه کارتر هستن و هنوز وارد بازار کار نشدند. این دسته افراد خیلی بیشتر آسیب میبینن چون تا حالا حقیقت ماجرا که اکثر شرکت ها به شدت نسبت به تغییر این دسته از تکنولوژی ها گارد دارن رو لمس نکردن و همین موضوع باعث ناراحتی و ترس خیلی زیادی میشه. نکته جالبی که در این ویدیو میبینیم جدا از زاویه دید فنی. زاویه دید بیزینسی هم رو میبینیم که چطور تیم فنی #Netflix رو تحت تاثیر خودش گذاشته که به عنوان مثال درمورد مهاجرت کدبیس ها از #Java 8 به #Java 17 صحبت میکنه که در چندسال پیش انجام شده و این رو به عنوان یک نکته مهم بیان میکنه و درموردش و تاثیراتش صحبت میکنه. دوباره با این حال بعد از این همه تلاشی که کردن روی ورژن های مثل 21 یا 24 که جدیدتر هستن نیومدن و قطعا تا سال چند سال آینده روی همین java 17 خواهند موند. نکته بعدی خود #Java هست؟ چرا باوجود چیزایی مثل #Golang #Rust از زبانی که برای boomer ها بوده استفاده میکنن؟ خب جواب این هست چرا اصلا استفاده نکنن؟ اکوسیستم خوبی داره سرعت بالایی داره و از همه مهم تر خیلی خیلی Stable هست و از نظر هزینه براشون به صرفه نیست که مهاجرت کنن روی تکنولوژی های دیگه. این صحبت ها به این معنی نیست که #Java خوب هست یا #Golang یا بقیه زبان ها بد یا خوب هستند. هدف صحبت امروز بیشتر این هست که لزوما برای موفق بودن همیشه نیازی نیست آخرین فریمورک آخرین تکنولوژی Backend خفن رو بلد باشیم. هنوز هم کدبیس های #COBOL هست و #CLang و #C++ به این زودی ها جایی نمیرن و البته چقدر شرکت هایی وجود داره که روی Java 8 و .NET 3.5 هستن و البته #PHP هم هنوز نمرده و نشانه هایی از مردن هم نداره جز در ویدیو های Tech influencer ها. https://www.youtube.com/watch?v=XpunFFS-n8I
18
1.2K
5
4
به این خط ساده و کوچک دقت کنید، توانایی این رو داره هرپروژه #FrontEnd و #BackEnd که با #NodeJS توسعه داده شده رو تبدیل به جهنم کنه. throw 1; اگر در #TypeScript براتون سوال پیش اومده که چرا در try catch statement تایپ err نامشخص هست، دقیقا بخاطر این موضوع هست. به این دلیل که هر نوع Object رو میشه throw کرد (این خیلی ترسناکه) و چون #JavaScript مفهومی به اسم Compile Time Error نداره و با توجه به طبیعت Dynamic و البته مفسری که #JavaScript داره منطقی هست که شما وقتی try catch استفاده میکنی type برای error تا زمان runtime مشخص نباشه. با مثال پایین بیشتر به عمق مسئله پی میبرید. try { throw { hoo: "Pop up from stack , NodeMaster" }; } catch (err /* type => unknown */) { console.log(err); } معمولا بعضیا با استفاده از type cast تایپ error رو تبدیل به Error میکنن مثل کد زیر که این به نوع خودش میتونه یک فاجعه دیگه باشه ( آخه نابغه اگر تایپ مشخص بود که Error هست #TypeScript همون اول خودش Error میزاشت و نیاز به Type Cast نبود دیگه) try { throw { hoo: "Pop up from stack , NodeMaster" }; } catch (err) { console.log((err as Error).message); // WTFFFFFFFFF !!!! } خب حالا سناریو های بد رو دیدم چطور جلوگیری کنیم؟ در پروژه های #FontEnd تنها روش خیلی خوبی که وجود داره استفاده از instanceof هست در #NodeJS برای #BackEnd هم میشه از این روش استفاده کرد ولی یک تکنیک دیگه وجود داره که اون بیشتر برای سناریوهای خیلی خاص #NodeJS هم کاربردی هست. try { throw { hoo: "Pop up from stack , NodeMaster" }; } catch (err) { if (err instanceof Error) { console.error("it's valid error object", err); } else { console.error("WHAT THE F IS THIS ???", err); } } برای پروژه های #NodeJS در std مربوط به Node یک فانکشن کمکی هست به اسم isNativeError که همین کار instanceof رو میکنه. حالا سوال پیش میاد که چرا باید از این استفاده کنیم؟ در حالت هایی به عنوان مثال استفاده از "node:vm" و ایجاد یک context جدید میتونه دردسر ساز بشه و instanceof نتونه تشخیص بده Error رو که نتایجش هم مشخصه. نکات دیگه ای هم وجود داره که پیشنهاد میکنم داکیومنت مربوط به این بخش رو بخونید کامل با مثال ساده توضیح داده. import { types } from "node:util"; try { throw { hoo: "Pop up from stack , NodeMaster" }; } catch (err) { if (types.isNativeError(err)) { console.error("it's valid error object", err); } else { console.error("WHAT THE F IS THIS ???", err); } } حالا یک سوال دیگ شاید براتون پیش بیاد که چرا اینقدر بدبینانه به مسئله نگاه میکنیم؟ تو دنیایی که #NPM وجود داره اعتماد به پکیج های 3RD Party گاهی اوقات میتونه گرون تموم بشه. شاید اون پکیج که استفاده میکنید این داستان رو رعایت نکرده باشه. پس بهتره ما دقت کنیم تا از runtime ارور های نصف شب جلوگیری کنیم و با آسوده بخوابیم.
16
1.2K
10
22
یکی از کسایی که در کامینیوتی #NodeJS میتونید خیلی چیزا ازش یاد بگیرید Matteo Collina سازنده فریم ورک #Fastify و کلی ابزار Open source دیگ برای #NodeJs . تا حالا چندین ویدیو از ایشون دیدم و خیلی نکات ریزی رو یاد گرفتم که اگر خودم بخوام به اون ها برسم رسما سال ها زمان میبره. پیشنهاد میکنم این ویدیو رو حتما ببینید. - نکته جالبی که در این ویدیو برای من بود عمق فریم ورک #Fastify بود که به برای ریز ترین مشکلات هم یک راه حلی وجود داره. - من شخصا با #Jest به شدت مشکل دارم و در این ویدیو یک دلیل بسیار بسیار ترسناک و بزرگ رو اشاره میکنه که این مشکل رو به تنفر نسبت به #Jest تبدیل کرد. https://www.youtube.com/watch?v=HyOuKN6KYqo
11
1.2K
36
1
دوستان که با من کم و بیش درمورد roadmap و یا نظرم رو درمورد مسیرشون پرسیدن همه میدونن من چقدر شخصا روی مبحث database و db design خیلی تاکید زیادی دارم. در این توییت یک کتاب که مدتی هست دارم میخونم معرفی کردم و نکاتی هم کلی گفتم. https://x.com/imanhpr_media/status/1808176854945177927?t=6qvq2I-HaKufcJh4a0KGSQ&s=19 این کتاب خیلی کتاب با ارزشی هست و برا من حکم یک سلاح مخفی داره و خب باعث competitive advantage زیادی برای من شده. #Book
12
1.2K
23
26
یکی از معجزه های #JavaScript ویژگی Closure هست. البته هر زبانی که این ویژگی رو داشته باشه خیلی دست بازی برای پیاده سازی پترن هایی داره که بدون Closure ها شاید ممکن نباشه. خیلی وقت پیش درمورد Async Cps Style صحبت کردیم میتونید برید نگاهی بندازید. نکته ای که میخوایم امروز درموردش صحبت کنیم این که چه جادویی در این تکه کد ساده که به صورت روزانه مینویسیم و کار میکنیم وجود داره ولی خیلی ساده ازش رد میشیم چون کار میکنه! ولی داستان از فقط کار کردن پیچیده تره! function asyncCPSTask(cb) { const localScope = "localScope"; function innrerFn() { cb(localScope); } setTimeout(innrerFn, 1000); } asyncCPSTask((data) => console.log(data)); در این کد یک localScope داریم که مستقیما اشاره داره که این variable در localScope مربوط به asyncCPSTask تعریف شده و در حالت عادی وقتی به پایان فانکشن مربوطه میرسیم و از call stack خارج میشیم، localScope هم باید خارج بشه و رسما دیگه نداریمش. ( اگر هم refrence type باشه که GC زحمتش رو باید بکشه ) اگر نکته بالا رو در نظر داشته باشیم باید انتظار داشته باشیم که console.log به ما مقداری رو نشون نده چون به کمک setTimeout یک delay داریم برای اجرا کردن innerFn که قطعا در iteration های بعدی Event-loop اتفاق میافته و صدرصد مطمئن هستیم که تا اون موقع asyncCPSTask از call stack خارج شده. با وجود این موضوع که ما رسما از call stack خارج شدیم و runtime برای ما innerFN رو داخل iteration های بعدی Event-loop اجرا میکنه باز هم مقدار localScope رو میبینیم. دلیل این اتفاق و این رفتار Closure هست. حالا برای درک بهتر این موضوع دوست دارم دقیقا متن کتاب JavaScript The Definitive Guide - David Flanagan (صفحه 204 بخش 8.6) بیارم: Like most modern programming languages, JavaScript uses lexical scoping. This means that functions are executed using the variable scope that was in effect when they were defined, not the variable scope that is in effect when they are invoked جمله دوم دقیقا ساده ترین و قشنگ ترین تعریف برای این رفتار هست. به دلیل این که innerFn در زمان تعریف در local scope مربوط به asyncCPSTask قرار داشته میتونه از اون scope استفاده کنه و ما چون در innerFn یک refrence به متغییر localScope داریم رسما asyncCPSTask رو تبدیل کردیم به یک Closure برای innerFn و باتوجه به این که در این حالت مهم نیست فانکشن از کجا call میشه و فقط نکته مهم این هست که کجا تعریف شده فانکشن. حالا چه event-loop برای ما فانکشن رو کال کنه چه خودمون در هر صورت دسترسی به localScope داریم. خیلی وقت پیش یک نگاهی به این ویژگی تقریبا داشتیم و باهاش decorator pattern رو به صورت کاربردی پیاده سازی کردیم و دیدیم. https://t.me/NodeMaster/115
10
1.2K
7
اگر درحال یادگیری #NestJS هستید و یا مدت زیادی هست با این framework محبوب کار میکنید به این نکته حتما توجه کنید. 1. به هیچ عنوان از Nest CLI برای ایجاد یک پروژه جدید استفاده نکنید. 2. حداقل اگر استفاده میکنید سعی کنید dep های اضافه رو پاک کنید. درمورد نکته اول یک اتفاق فاجعه بار درصورت رعایت نکردن میتونه رخ بده. اگر با Nest CLI پروژه ایجاد کنید و بعد به tsconfig یک نگاهی بندازید همچین خطی رو میبینید. { "strictNullChecks": false } همین یک خط config توانایی این رو داره که پروژه رو تبدیل کنه به میدان مین جنگی و گوشی شما یکهویی ساعت ۱ شب زنگ میخوره کارفرما به شما میگه رو production مشکل داریم و بعد از چک کردن log ها متوجه Null pointer های زیبا خواهید شد. قبلا درمورد این موضوع یعنی Null References: The Billion Dollar Mistake در این پست مفصل صحبت کردیم. https://t.me/NodeMaster/84 این نکته خیلی میتونه ترسناک باشه به این دلیل که اگر کسی تازه داره روی کد onboard میشه اگر معمولا فرض بر این داره که #TypeScript کمک به Null safe بودن داره و نکته جذاب اینجا هست که ترکیب false بودن این flag با همچین تصور پیشفرضی به زیبایی میتونه جهنم باشه ( به قول خارجی ها road to disaster ). چندتا config دیگ هم مربوط به safety به صورت پیش فرض در این حالت false هستن که هیچ کدوم به اندازه این ترسناک نیستن. در ادامه اگر روی یک code base بزرگ باشید و این flag مهم از قبل false بوده بعد از true کردن این flag پروژه شما در کسری از ثانیه به رنگ خون در میاد و فرایند refactor کردن در این سناریو فرایندی بسیار هزینه بر هست. پس بهتره از همون اول پروژه این رو درنظر بگیرید. درمورد نکته دوم این که به صورت پیش فرض #NestJS یک سری Dep به پروژه از این روش اضافه میکنه که ممکنه اصلا نیازی بهش نداشته باشید و خب این یک bad practise محسوب میشه ( YAGNI Principle ). این حالت زمان build time هم الکی اضاف میکنه و در پروژه بزرگ میتونه آزار دهنده باشه. موضوع بعد در این مورد این که بعضی از package هایی که وجود دارن در package.json آپدیت نیستن و خیلی سریعتر از زمان معمول ممکنه نیاز به آپدیت کردن پروژه داشته باشید. با نصب کردن dep ها به صورت دستی حداقل از این موضوع میتونید اطمینان پیدا کنید که از جدیدترین ورژن پکیج ها دارید استفاده میکنید. #Tip #NodeJS
11
1.3K
14
15
اگر در پروژه خودتون CI/CD دارید برای نصب dependency های پروژه #NodeJS خودتون اگر از #NPM استفاده میکنید یادتون باشه که از ci استفاده کنید npm ci هدف از استفاده این command برای استفاده در محیط هایی مثل CI میباشد یا در حالتی که میخواید یه نصب تمیز داشته باشید روی محیطی که دارید اجرا میکنید برنامتون رو. تفاوت هایی که این روش با npm install داره چیه ؟ - حتما و حتما باید package-lock.json داخل پروژه شما باشه. - اگر package-lock.json نبود با در حقیقت نصب ما ادامه پیدا نمیکنه و package-lock.json جدید آپدیت ایجاد نخواهد شد. - اگر node_modules وجود داشته باشه ( در سناریو هایی که فراموش میشه به عنوان مثال در .gitignore بزاریم ) قبل از نصب حذف میشه و یک node_modules جدید ایجاد میشود. - هیچ وقت package.json آپدیت نمیکنه و دقیقا همون چیزی هست که ما موقع ci میخوایم. معادل این روش رو تقریبا میتونید روی pnpm هم به این شکل داشته باشید. pnpm install --frozen-lockfile و معادل این روش در Yarn yarn install --frozen-lockfile به صورت کلی اگر در محیط production میخواید پروژه خودتون رو اجرا کنید باید یطوری dep ها رو نصب کنید که از package-lock این عملیات صورت بگیره. هم سریعتر هست و هم تضمین بر این که dep hell نخواهید داشت.
12
1.3K
10
دوستان ofood پوزیشن خالی Nodejs #Work https://twitter.com/mh_daneshvar/status/1793312352286232933?t=dVDwvqfRzUWSf64mvIhflA&s=19
1.3K
7
2
همیشه ما همه تلاش داریم کد با Performance خوب توسعه بدیم بدون این که این موضوع رو تصور کنیم که داخل کدبیس های #JavaScript معمولا Performance شوخیه. ولی امروز قراره درمورد یک ویژگی جدید که در آپدیت ES2025 به #JavaScript اضافه شده صحبت کنیم که بهمون کمک میکنه که Performance بهتری داشته باشیم. سمت #NodeJS در بیزینس لاجیک های پیچیده میتونه معجزه کنه. برای #FrontEnd هم کاربردی هست ولی باتوجه به این که مرورگر های قدیمی ساپورت نمیکنن خب قطعا به این زودی استفاده ازش رو نمیبینیم. ویژگی جدید ما اضاف شدن یک static method جدید به Iterator هست. Iterator.from() حالا سوال پیش میاد که چطور این به ما کمک میکنه. فرض کنید یک array بزرگ دارید و میخواید data رو map کنید به یک شکل دیگه و برای این کار یک pipeline از map ها رو ایجاد کردید: const data = [1, 2, 3, 4, 5]; const final = data .map((item) => item.toString()) .map((item) => `- ${item} -`) .map((item) => `${item} ${new Date()}`); در نگاه اول مشکلی نداره ولی اگر با عینک Performance ببینیم دوتا مشکل میبینیم. 1. برای هر map مجبوریم یکبار کامل loop بزنیم خب 3 بار loop میزنیم پس داریم O(3n) 2. هربار که یک loop کامل میزنیم هربار داریم یک Array جدید بعد از map ایجاد میکنیم. به صورت خلاصه هر .map برابر هست با یک Array allocation جدید. خب اینجا یک array اورجینال داریم و 3 تا map پس 4 تا array allocation داریم. ممکنه برای تازه کارترها سوال های زیر پیش بیاد: 1. خب چرا اصلا این استایل کد میزنیم؟ 2. چرا همه رو داخل یک map انجام نمیدیم؟ پاسخ سوال اول: - میتونیم با for ... of کار رو بهتر با یک loop در بیاریم ولی مسئله این هست که معمولا برنامه نویس های #JavaScript در اینجور مواقع حتی بدون این که خودشون بدونن دیدگاه Functional Programming دارن و خب از اونجایی که به صورت فلسفی FP ذات Declarative داره و به صورت فلسفی کار کردن با API ها Declarative خیلی راحت تر و لذت بخش تر از Imperative هست همچین چیزی رو میبینیم. - اگر هم خیلی کنجکاوید بیشتر بدونید وقتش هست نگاهی به #Elixir #Scala یا حتی Lambda ها در #Java اونجا قشنگ متوجه میشید. یا اصلا مسیر رو برعکس برید و نگاهی به رویکرد #Golang کنید و فرق زمین تا آسمونی رو ببینید. پاسخ سوال دوم: - در بزینس لاجیک های پیچیده برای خوانایی کد داشتن map های بیشتر خیلی بهتر از این هست که یک map بزرگ داشته باشیم. منطقی هم هست چون خیلی بهمون God Object ها رو یادآوری میکنه. خب حالا سوال پیش میاد چیکار کنیم؟ خیلی ساده هست کافیه فقط خط اول رو به این شکل عوض کنیم و array رو تبدیل کنیم به Iterator. const data = [1, 2, 3, 4, 5, 6]; ❌ const data = Iterator.from([1, 2, 3, 4, 5, 6]); ✅ خب دوباره الان سوال پیش میاد که WTF الان چی شد؟ سادس. ما دیتا رو تبدیل کردیم به یک Iterator که ذات Iterator ها به صورت Lazy هست یعنی تا وقتی که نیاز به consume شدن data نباشه هیچ پردازشی انجام نمیشه و اگر هم نیاز به map کردن باشه دقیقا در runtime به صورت on-demand برای هر index تبدیل انجام میشه و ما نیازی به alloc کردن حافظه اضافه برای Array نداریم و هیچ loop اضافه ای هم درکار نیست. حالا به این نکات توجه کنید: - هر iterator رو فقط یکبار میشه consume کرد و اگر نیاز باشه باید دوباره ازش بسازی. در حقیقت با .toArray داریم consume کردن رو شبیه سازی میکنیم و دومی مقدار خالی به ما میده به خاطر iterator بودن. const data = Iterator.from([1, 2, 3, 4, 5, 6]); data.toArray() data.toArray() - در این قسمت به map ها باید توجه کرد که با هر بار call شدن یک Array جدید نمیسازن بلکه یک Iterator جدید که روی Iterator قبلی سوار هست رو به ما میده! پس در نتیجه با توجه به تعریف Iterator که بالاتر گفتم نه loop اضافه ای داریم و نه alloc اضافه. const data = Iterator.from([1, 2, 3, 4, 5, 6]); const final = data .map((item) => item.toString()) .map((item) => `- ${item} -`) .map((item) => `${item} ${new Date()}`); حالا اگر یکم بیشتر دقت کنی میبینیم خیلی شبیه به stream ها هست. اصلا این دوتا api به شدت باهم سازگار هستن. در این حد که استریم ها رو میشه تبدیل کرد به iterator و برعکس. بقیه کد هم دقیقا به صورت مشابهه کار میکنه. import { Readable } from "node:stream"; const data = Iterator.from([1, 2, 3, 4, 5, 6]); const streamData = Readable.from(data); دل نوشته: حقیقتا دیگ نمیشه تفاوت بین stream, iterator, generator, rxjs, web stream, رو تشخیص داد😂. همشون رو میتونی جایگزین هم استفاده کنی. ( دلایل مختلفی برای وجود این همه api برای یک کار هست )
16
1.3K
17
6
مدت زیادی هست که #Redis Stack منتشر شده ولی هنوز خیلی ها به Redis به چشم یک دیتابیس Key-Value ساده نگاه میکنند و از 90 درصد قابلیت هاش استفاده نمیکنند. پیشنهاد میکنم داکیومنت مربوط بهش رو حتما بخونیدتا تمام ویژگی هایی رو که داره ببینید. دوتا از ویژگی های خوبی که Redis Stack داره به اسم Redis Search و Redis JSON هست. - تا قبل از Redis JSON برای ذخیره کردن JSON ها در Redis، معادل Serialize شده رو به صورت Key-Value ذخیره میکردن و یا گاهی به صورت Map باهاش رفتار میکردن. حالا شما با Redis JSON میتونید مثل یک document oriented database مثل MongoDB رفتار کنید. ( البته Query ها به صورت پیش فرض محدودیت هایی دارند ) - تا قبل از Redis Search برای سرچ کردن تنها گزینه موجود استفاده از Glob Pattern ها بود که حتی داخل خود داکیومنت هم پیشنهاد کرده بودن که اگر روی Production هستید سعی کنید زیاد استفاده از Glob pattern نکنید. و این موضوع با در نظر گرفتن این نکته که Redis به صورت ذاتی Single thread هست و Event loop رو با این کار در حجم زیاد دیتا بلاک میکنید منطقی هست. البته این موضوع برای دوستان #JavaScript و #NodeJS کاملا به صورت واضح قابل درک هست. حالا شما با استفاده از Redis Search میتونید روی دیتا مورد نظرتون Index بزارید و باتوجه به اون Index و Schema که تعریف کردین Query بزنید و دیتا رو خیلی سریع و تمیز دریافت کنید. انتظار قدرت SQL و بقیه دیتابیس ها مثل MongoDB رو نداشته باشید ولی در بعضی سناریو ها واقعا ترکیب Redis Json و Redis Search میدرخشه. در این مثال با نحوه کار کردن با Redis JSON آشنا میشیم و در پست بعدی با Redis Search یک خورده کار میکنیم. به صورت کلی شما با استفاده از "JSON" میتونید دسترسی به namespace مربوط بهش رو داشته باشید و با json ها کار کنید. - ایجاد یک Json doc جدید JSON.SET key path value با استفاده از JSON.SET میتونید JSON به راحتی ذخیره کنید. در اینجا key منظور از همون کلید عادی هست نکته خاصی نداره ( در Redis Search درموردش بیشتر صحبت میکنیم ). منظور از Path اینجا مسیر JsonPath هست که با استفاده از اون میتونید فیلتر های مختلف روی دیتا Json بزارید و بخش خاصی رو فقط بخونید یا آپدیت کنید ( معادل Xpath برای داده های XML ). برای این که بتونیم یک دیتا json ذخیره کنیم خب ما میخوایم در مسیر Root این کلید ذخیره کنیم و با استفاده از "$" مشخص میکنیم که میخوایم روی Root ذخیره کنیم. JSON.SET user:1 $ '{"name": "Iman", "age": 25, "city": "Bushehr"}' حالا اگر بخوام فقط بخش name رو بخونم از این به این صورت عمل میکنم. JSON.GET user:1 "name" یا اگر بخوام شهر رو آپدیت کنم به تهران. JSON.SET user:1 $.city '"Tehran"' حالا اگر بخوایم کل دیتا بخونیم و نتیجه رو ببینیم. JSON.GET user:1 یک نکته خیلی مهم و ریز درمورد آپدیت بگم. جایی که دیتا رو قرار میدیم یعنی '"Tehran"' هر مدل دیتایی میخواد باشه مثل اینجا که یک string ساده هست. باید یک parser مربوط به JSON بتونه به صورت Valid این دیتا رو Serialize کنه. به عنوان مثال یعنی عبارت زیر در #JavaScript باید بدون هیچ خطایی کار کنه. > JSON.stringify("Tehran") '"Tehran"' در صورتی که JSON.stringify به شما خروجی داد شما اون دیتا رو میتونید به عنوان value استفاده کنید. حالا برا این که مثال رو یکم جالب تر کنیم یک Json دیگ رو داخل این Embed میکنیم. JSON.SET user:1 $.address '{"zipCode":1234}' JSON.GET user:1 $.address.zipCode در پست بعدی به Redis Search نگاه میندازیم و اگر انرژی هم موند یکی از مهم ترین و اساسی ترین نکات Redis که دونستنش میتونه مثل مرگ و زندگی باشه یعنی Atomicity رو برسی میکنیم. امیدوارم موفق باشید.
19
1.3K
14
5

👇 استخدام نیروی سنیور NestJs 👇 👋 باسلام و درود و ارادت 😎 خدمت برنامه نویسان محترم 💎 دوستان 🌦 Nest کاری که میدونن مهارت کافی برای انجام پروژه دارن، لطفا دایرکت رزومه ارسال کنن 📌 لوکیشن: ریموت 🌐 ⚡️ مزایا: در مصاحبه بعد از تایید رزومه 🔗 پیش نیاز ها: ◀️ تسلط به Nest ◀️ تسلط به Sequelize ◀️ تسلط سوکت ◀️ تسلط کافی به ساختار و بنای HTTP ◀️ داشتن و تجربه کار با محیط های پروداکشن، استیجینگ ◀️ دانستن روش های مختلف اتصال و تفکیک کانفیگ های داخلی و خارجی (برنامه و دوآپس) ❗️ طبعا ممکنه هممون برخی از موارد بالا رو ندونیم و یا شرکت با شرکت متفاوت باشه؛ ایرادی نداره! لطفا رزومتون رو بفرستین بدون نگرانی از کمبود اطلاعات. امیدوارم که قبول بشین ✔️💪 👀 آیدی جهت ارسال رزومه: ▶️ @mostafa_effati #Work
5
1.3K
10
3
چندین بار سعی کردم با معماری #Microservice دقیق تر آشنا بشم ولی همیشه به دلیل پیچیده بودن pattern ها لینک کردن بین مطالب زیاد موفق نبود و البته یکی از منابع خوبی که برای عمیق شدن وجود داره کتاب Building Microservices Book by Sam Newman هست. امروز این دوره 2 ساعته رو نگاه کردم. به صورت خیلی Big picture درمورد #Microservice صحبت میکنه و البته بعضی مفاهیم هم با code snippet های خیلی ساده #NodeJS و #Express توضیح میده. پیشنهاد میکنم اگر قصد دارید #Microservice عمیق تر بشید و اگر مثل من زیاد در این مورد نمیدونید اول این دوره رو نگاه کنید و بعد مفاهیم و نکات این دوره رو هرکدوم به عنوان یک سرفصل یا سرتیتر برای مطالعه بیشتر و عمیق تر شدن استفاده کنید. به نظرم مقدمه خوبی هست قبل از مطالعه کتابی که بالاتر گفتم. https://downloadly.ir/elearning/video-tutorials/node-js-microservices-the-big-picture/ #course
16
1.3K
57
1
یک بخش جدید به داکیومنت #NodeJS از ورژن 22 اضافه شده برای TypeScript. خودش پیشنهاد میکنه از tsx استفاده کنیم برای NodeJS. به صورت کلی فاصله زیادی داریم تا #NodeJS هم مثل #Bun و #Deno به صورت کامل و Stable از #TypeScript ساپورت کنه. داخل این داکیومنت در این مورد توضیحات مربوطه داده شده. درکل برای پروژه Production درکل tsx یا ts-node گزینه منطقی تری هست. https://nodejs.org/docs/latest-v22.x/api/typescript.html #Update
11
1.3K
6
یکی از بچه های گروه خودمون ظاهرا یک پوزیشن باز داخل شرکتشون دارن. دوست داشتید یک چک بزنید. https://ttr.ir/azjb #Work
1.4K
2
بلاخره بعد از سال ها نسخه 5 برای #Express منتشر شده میتونید تغییرات رو از اینجا ببینید و تستش کنید. https://github.com/expressjs/express/releases/tag/v5.0.0 کلا این روزا اگر پروژه ای دارید به نظر من از هرچیزی جز #Express استفاده کنید به نظر من بهتره
13
3
1.4K
5
67
با سلام خدمت همگی دوستان. من فکر میکردم امروز یک ساله میشه چنل ولی ظاهرا ۳ روز پیش بوده.😂 از همه شما خیلی خیلی ممنونم که در این یک سال همراه من بودین و باهم خیلی چیز ها یادگرفتیم و پیشرفت کردیم. واقعا همیشه دوست داشتم یک کامینیوتی برنامه نویسی عضو باشم که بچه ها فعال باشن و بحث ها عمیق داشته باشیم که با کمک شما تونستم به این آرزو در این یک سال برسم و واقعا از شما خیلی خیلی ممنونم🔥 امیدوارم تونسته باشم در این مدت براتون مفید بوده باشم و این برای من خیلی با ارزش هست. در ادامه باهم دیگه قوی تر جلو میریم چیز های جدید و عمیق تر یاد میگیرم و بابت این موضوع خیلی خیلی هیجان دارم و خوشحال. برای همه شما آرزو موفقیت و خوشبختی دارم. داداش کوچک شما ایمان ❤️
42
1.4K
10
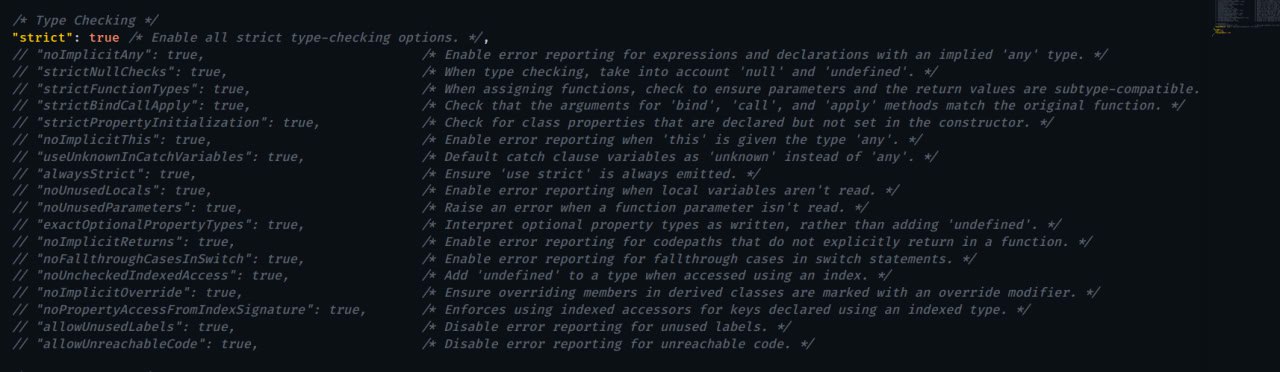
ترسناک تر از Dynamic Type بودن #JavaScript در حقیقت پروژه #TypeScript هست که به تو توهم Type safe بودن بده. هروقت پروژه #TypeScript دیدین اول بیاین این قسمت رو چک کنید که مثل عکس بالا strict باشه و هیچ کدوم از flag های زیرش false نباشه. اگر در موقع کار با #TypeScript مجبور شدین اینجا فلگی رو false کنید این برداشت رو میتونید کنید که #TypeScript بلد نیستید!
19
1.4K
8
درود خدمت شما دوستان. const lst = [] lst.map() موضوعی که امروز در این ویدیو میخواهیم عمیق درموردش صحبت کنیم این هست که چرا همین یک خط کد کوچک در بالا باعث میشه سرور #NodeJS نابود بشه و کلا نتونه هیچ Response رو به کاربر بده. در این مسیر نگاهی میکنیم به یکی خفن ترین ویژگی های #NodeJS یعنی Readable استریم ها و یاد میگیریم که چطور با استفاده از اون ها یعنی Readable.from() یک برنامه بسیار Optimize تری داشته باشیم. https://youtu.be/N0akLbvhShE?si=f623-vxXz-brA4ag
13
1.4K
21
59
به نسخه LTS آینده یعنی 22 در آپدیت 22.5 پکیج node:"sqlite اضافه شد. البته این نکته قابل ذکر هست که این پکیج stable نیست و در حال توسعه میباشد. https://nodejs.org/docs/latest/api/sqlite.html
4
1.4K
2
9
درود و وقت بخیر دوستان. یکی از نکاتی که خیلی میتونه بهتون کمک کنه به عنوان Backend developer دانش شبکه هست. متاسفانه اکثر دوره های شبکه برای بچه های Developer ممکنه یکم درکشون سخت باشه چون از زاویه Network engineering بهشون نگاه میشه و نه development. در نهایت دوره های شبکه رو هم حداقل پایه ای رو باید گذروند اما چند روز پیش این دوره کوتاه ( ۲ ساعته ) رو دیدم و به نظرم مفاهیم شبکه رو در حد خوبی با زبانی که برای developer ها ساده باشه و پایه خوبی باشه برای دوره هایی مثل Network+ میتونید ببینید. https://downloadly.ir/elearning/video-tutorials/introduction-to-computer-networking-2-hour-crash-course/ البته نسخه که داخل یودمی هست یکم آپدیت شده و ابن نسخه دانلودلی ناقص تر هست ولی همین رو هم ببینید خوبه. امیدوارم موفق باشید
19
1.4K
51
34
امیدوارم حالتون خوب باشه دوستان. داخل آپدیت ES2025 یک static method جدید برای به اسم Promise.try اضافه شده و در این پست باهم برسیش میکنیم. https://telegra.ph/%D9%85%D8%AA%D8%AF-%D8%AC%D8%AF%DB%8C%D8%AF-Promisetry-%D8%AF%D8%B1-ES2025-07-21 البته به صورت تستی با استفاده از telegra.ph شاید بهتر باشه
13
1.4K
4
8
1.5K
26
یکی از نکات زیبا که درمورد #Deno و #JSR که وجود داره این هست که شما میتونید از پکیج های std دینو در #NodeJS استفاده کنید. همشون نه ولی به اکثرشون دسترسی دارید. به لینک زیر یک نگاهی بندازید و مشخصا میبینید که کدوم پکیج ها رو میتونید در پروژه #NodeJS خودتون استفاده کنید. https://jsr.io/@std به عنوان مثال پکیج @std/msgpack به پروژه خودمون اضافه میکنیم. npx jsr add @std/msgpack و بعد کد زیر رو با #NodeJS اجرا کنید. import * as msgpack from "@std/msgpack"; const data = { name: "node-master" }; const enc = msgpack.encode(data); const dec = msgpack.decode(enc); console.log(dec); حالا سوال پیش میاد که اصلا چرا همچین کاری باید کنیم. باتوجه به این که #JavaScript خودش std بزرگی مثل #Python یا #Java نداره گاهی اوقات نیاز به یک سری کدهای کمکی برای پروژه خودتون دارید و پکیج هایی مثل Lodash, es-toolkit کمک بزرگی کردن. اما حالا #Deno هم با این کار به اکوسیستم کمک بزرگی کرده و یک رنج از ابزار های کمکی که ممکنه در loadash و بقیه شبیهه بهش پیدا نکنید رو شاید اینجا پیدا کنید. به عنوان مثال اگر پروژه کوچیکی دارید که فقط یک instance از server شما وجود داره استفاده از ابزاری مثل #Redis صرفا برای Cache زیاد منطقی نیست و خب در اکثرا اوقات یک Map ساده مشکل شما رو میتونه حل کنه. اگر ویژگی TTL هم بخواید داشته باشید خودتون میتونید پیاده سازی کنید با کمک Map ولی معمولا از پکیج node-cache در این سناریو استفاده میکنن. حالا یک گزینه دیگ داریم که مربوط به #Deno std هست. https://jsr.io/@std/cache این پکیج جدا از مثال بالا مدل های مختلف دیگ از cache رو در اختیار شما میزاره که نگاهی بندازید و جالبه.
5
1.5K
1
2
درود دوستان ارادت. امیدوارم حالتون خوب باشه. // lib code func doSomething() <-chan int { ch := make(chan int) go func() { defer close(ch) time.Sleep(2 * time.Second) ch <- 102 }() return ch } // main code func main() { result := <-doSomething() fmt.Println(result) } همیشه مفهوم Concurrency برای ما Developer ها مثل یک Super Power هست و البته به دست آوردن این Super Power هم کار راحتی نیست. قبلا کتاب Learning Go رو من مطالعه میکردم و یک پاراگراف از این کتاب برای من خیلی جذاب بود چون نگرش من درمورد این موضوع و این Super Power تا حد خیلی زیادی تغییر داد. در این ویدیو سعی میکنیم یک طرز تفکر و یک رویکرد رو برسی کنیم که بتونیم در آینده زیر ساخت مناسبی برای شنا کردن در دریای عمیق Concurrency ها در آینده داشته باشیم. نکته اصلی این ویدیو مفهوم و طرز تفکری هست که از اون پاراگراف در کتاب یاد گرفتم و امیدوارم تونسته باشم به خوبی اون رو منتقل کنم. https://youtu.be/fbh_r9CKmMU
14
1.5K
9
1
درود و خسته نباشید دوستان امیدوارم حالتون خوب باشه. اگر با lib هایی مثل #jest و #vitest برای پروژه هاتون تست نوشته باشید و البته بعد تلاش کرده باشین که سوییچ کنید روی std test runner خود #NodeJS که خیلی هم از Stable شدنش نمیگذره. یکی از بزرگترین مشکلاتی که این Test runner داشت و تست نوشتن رو در یک سناریو واقعا آزار دهنده میکرد در آپدیت 22.17 LTS فیکس شده. assert.partialDeepStrictEqual() گاهی اوقات پیش میاد که میخواید یک subset از یک object رو assert کنید و نمیخواید کل اون attr های اون object رو assert کنید. تا قبل از این آپدیت این سناریو در STD test runner غیرممکن بود. شخصا واقعا خوشحالم که این رو خیلی سریع متوجه شدن و اضاف کردن چون همه چیزش خیلی خوب شده و فقط همین یدونه کم بود.
11
1.5K
1
درود دوستان امیدوارم حالتون خوب باشه. ورژن #NodeJS جدید 24.11 به صورت LTS منتشر شد. https://nodejs.org/en/blog/release/v24.11.0
19
1.5K
2
13
در پست قبلی درمورد #Redis JSON برای ذخیره کردن Document ها و Query های مربوط به این بخش آشنا شدیم. امروز نگاهی به Redis Search میندازیم و ترکیبش رو با Redis JSON برسی میکنیم. اولین نکته این که شما توانایی index کردن HASH ها و JSON ها رو دارید. یعنی اگر پروژتون الان روی HASH هست بدون هیچ دردسری میتونید از Query های Redis Search استفاده کنید. برای پست امروز با Redis JSON کار میکنیم باتوجه به این که مطالعه کوچیکی درموردشون داشتیم. اولین کاری که میکنیم #Redis رو با دیتا فیک Seed میکنیم. JSON.SET user:0 $ '{"name":"Farah","city":"Malibong East","age":21}' JSON.SET user:1 $ '{"name":"Wyn","city":"Hezheng Chengguanzhen","age":62}' JSON.SET user:2 $ '{"name":"Frederich","city":"Liujia","age":32}' JSON.SET user:3 $ '{"name":"Maria","city":"Tudela","age":47}' JSON.SET user:4 $ '{"name":"Marty","city":"Irtyshskiy","age":48}' JSON.SET user:5 $ '{"name":"Glendon","city":"Bagorejo","age":59}' JSON.SET user:6 $ '{"name":"Minne","city":"San Pedro","age":59}' JSON.SET user:7 $ '{"name":"Garrett","city":"Shuangpu","age":26}' JSON.SET user:8 $ '{"name":"Anna-diana","city":"Jalālpur","age":32}' JSON.SET user:9 $ '{"name":"Silas","city":"Qacha’s Nek","age":34}' درمورد کار کردن با JSON در پست قبلی توضیح دادیم. مرحله بعدی این هست که Index و Schema مناسب برای این دیتا ایجاد کنیم که بتونیم Query بزنیم. FT.CREATE idx:user ON JSON PREFIX 1 user: SCHEMA $.name AS name TEXT $.age AS age NUMERIC $.city AS city TEXT به FT.CREATE ما میتونیم ایندکس جدید ایجاد کنیم. این کامند بسیار آپشن های زیادی داره و پیشنهاد میکنم حتما داکیومنت مربوط بهش رو بخونید به عنوان مثال میتونید بعضی از Field ها که نیاز ندارید داخل Index قرار ندین ولی توی Schema شما وجود داشته باشه. برای امروز ما سعی میکنیم تا حد ممکن مثال رو ساده نگه داریم. - بخش اول یعنی idx:user اسم ایندکس یا به قولی Schema ما هست. اگر میخواید ببینید چه Index هایی دارید میتونید از FT._LIST استفاده کنید. - بخش دوم یعنی ON JSON تعریف میکنید که دیتا JSON هست و اینجا میتونید HASH هم بزارید. - بخش سوم که برای Performance مهم هست این هست که محدودیت Index ایجاد میکنید که روی تمام Key ها ایجاد نشه. اینجا ما گفتیم کلید هایی که پیشوند 'user:' دارن و اگر دقت کنید در بخش Seed هم تمامی کلید ها با 'user:' شروع میشوند. توجه کنید اگر دیتا شما با این پسوند شروع نشه index نمیشه و نمیتونید سرچ انجام بدین. اگر این بخش هم نزارید کل key ها رو index میکنه یعنی '*' که ما نمیخوایم. - بخش چهارم که Schema رو تعریف میکنیم با انواع data type ها. اول مسیر فیلد رو با #JSONPath مشخص میکنیم و بعد برای Query زدن با استفاده از AS براشون Alias میزاریم و البته در آخر نوع data type هم مشخص میکنیم. در اینجا age از نوع عددی هست و بقیه TEXT. در اینجا هم آپشن های متنوعی وجود داره مثل استفاده از Geo میتونید مختصات جغرافیایی بزارید و Query های خاص خودش رو استفاده کنید. مثلا در app های دوست یابی میخواین نزدیک ترین افراد رو به کاربر پیدا کنید. حالا یک سری Query رو با هم برسی میکنیم. مثلا افرادی رو میخوایم که بالا 30 سال سن دارن و از offset 0 شروع کن 2 تا نتیجه رو برای ما بیار FT.SEARCH idx:user '@age:[30 +inf]' LIMIT 0 2 اینجا هست که با استفاده از Alias هایی که بالا مشخص کردیم میتونیم Query بزنیم روی ایندکسی که میخوایم. حالا اگر بخوایم ادمایی که 34 سال دارن رو ببینیم. FT.SEARCH idx:user '@age:[34 34]' FT.SEARCH idx:user '@age==34' DIALECT 2 این دوتا Query برابر هستن از نظر خروجی. تنها تفاوت این هست که #Redis در Query lang که داره برای حفظ Backward compatibility سینتکس های جدید که اضافه میکنه رو با DIALECT دسته بندی کرده که در دومی DIALECT مدل 2 رو میبینم. حالا یکی رو میخوایم ببینیم که توی یک شهر خاص زندگی میکنه و میخوایم فقط اسمش رو ببینیم. FT.SEARCH idx:user '@city:San Pedro' RETURN 1 name حالا میخوایم تمام کاربرا رو بر اساس سن Sort شده ببینیم. FT.SEARCH idx:user '*' SORTBY age DESC اینجا جا داره بگم به قول خارجی های Sky is the limit کلی قابلیت دیگه وجود داره که واقعا ارزش برسی داره مثل Aggregate ها که قدرت خیلی زیادی داره یا کار کردن با Vector ها. هدف از این پست آشنایی با این بخش بود. در آینده بخش های بیشتری رو برسی میکنیم. امیدوارم موفق باشید.
7
1.6K
9
قبلا در مورد استفاده از jsonb در #postgres صحبت کردیم و به صورت خلاصه اشاره کردیم چرا میتونه خوب باشه. امروز دوباره قراره یک نکته دیگ که خیلی خیلی میتونه مفید باشه یاد بگیرم. این که چطور اطلاعات یک جدول رو تبدیل کنیم به json ؟ حالا سوالی که برامون پیش میاد اصلا چرا باید همچین کاری کنیم؟ به صورت کلی گاهی اوقات نیاز دارید در هنگام Query زدن اطلاعات مربوط به polymorphic table ها رو همه و همه با جزیات در یک Query ببینید. در #MySQL ظاهرا راه حل های Native برای این گونه مسائل وجود داره که در آینده باهم یاد خواهیم گرفت ولی در Postgres با کمک Json ها که آزادی عمل زیادی بهتون میده میتونید هر کاری کنید از جمله حل کردن این گونه مسائل. فرض کنید یک users table داریم با column های id, name , email. حالا میخواهیم تمام اطلاعات مربوط به هر row رو داخل یک column به اسم user_data داشته باشیم SELECT to_json(users) AS user_data FROM users; خب در اینجا ما از فانکشن کمکی to_json کمک گرفتیم که هر row در جدول users رو به json تبدیل کنیم که سطون های جدول users به عنوان key و مقادیر هر row به عنوان value در نظر گرفته میشود. این فانکشن کمکی به صورت کلی یکم محدود هست به این که کل سطون ها رو تبدیل به json میکنه. حالا اگر بخوایم قبل از json شدن روی دیتا مربوط به اون column های خاص یک کاری انجام بدیم مثلا type cast انجام بدیم چکار باید کنیم؟ اینجا json_build_object به نجات ما میاد. SELECT json_build_object( 'id', u.id :: TEXT, 'base_mail_name', split_part(u.email, '@', 1), 'fqdn', split_part(u.email, '@', 2) ) AS users_data FROM users AS u; اینجا رسما دیتا مربوط هر row رو میگیرم و دستی به شکلی که میخوایم در Result set نهایی داشته باشیم شکل میدیم. فانکشن json_build_object تعداد زوج از param ها رو میگیره که param های فرد به عنوان Key و param های زوج به عنوان Value نهایی ما در json هستن. فانکشن split_part هم مثل اینجا صرفا برای split کردن یک string هست مثل متد split در #JavaScript عمل میکنه. به صورت کلی فانکشن های کمکی خیلی زیادی برای کار کردن با json ها در #Postgres هستن ولی این دوتا بین اون ها خیلی کاربردی تر هستن. بقیه خیلی خیلی خاص تر هستن. کلا استفاده از همین ها هم خیلی نمیبینیم چون به صورت روزمره کاربردی نیستن ولی داخل سناریو های خاصی که بالا به یکیش اشاره کردم این ها کمک خیلی بزرگی میکنند. یا حتی در استفاده از Union برای ایجاد یک interface یکسان برای Table های مربوط در Query. نکته بعدی این که هردو فانکشن بالا ورژن jsonb هم دارند. to_jsonb jsonb_build_object درمورد Performance اطلاعات دقیق ندارم و بیشتر نظر شخصی خودم هست. - قطعا تاثیر منفی در Performance دارن ولی اونقدر کمک بزرگی میکنند که به هیچ عنوان این تاثیر منفی به چشم نمیاد برای مشکلاتی که از این روش ها استفاده میکنید. - معمولا مشکلاتی که بالا اشاره کردم شخصا در کدبیس ها دیدم که به هردلیلی سناریو های مختلف که از این طریق میشه رفت جلو رو، در سطح application هندل کردن که خب اونجا قطعا هم دردسر خیلی بیشتری داره برای توسعه هم نگهداری و هم البته وب سرور رو درگیر کاری میکنه که لزوما براش ساخته و بهینه نشده. در نتیجه اینجا اگر تمام این موضوعات در نظر بگیری فدا کردن یک کوچولو Performance دیتابیس خیلی منطقی به نظر میاد.
10
2
1.6K
4
29
من شخصا به عنوان یک #Python Hater دو آتیشه هستم. ولی یک چیزی داره و عجیب خوب هست. حداقل من تا حالا شبیهش رو داخل هیچ اکوسیستم دیگه ای ندیدم و اگر شبیهش رو میشناسید معرفی کنید خوشحال میشم. این ویژگی خیلی واقعا خفن pickle std برای #Python هست. در حقیقت pickle یک serialization format مثل #JSON هست و مثل #Protobuf یک فرمت binaray هست. حالا سوال پیش میاد چه نکته ای داره. شما به pickel هر object در اکوسیستم #Python رو میتونید serialize کنید. هر Object با تمام پیچدگی ها custom که داره. بزارید با مثال توضیح بدم. تصور کنید یک JSON دارید و اون رو میخواید map کنید به یک class و خب معمولا با Factory ها و به شکل های مختلف این اتفاق میافته. class User { constructor(name) { this.name = name; } static FromJsonString(input) { const result = JSON.parse(input); return new User(result.name); } } const runTimeInput = '{"name":"imanhpr"}'; const user = User.FromJsonString(runTimeInput); console.log(user instanceof User); console.log(user.name); همه چی خیلی منطقی کار میکنه در این سناریو. نکته جالب که اینجا و توجه بهش جالبه این هست که در اینجا به صورت ذاتی هیچ metadata وجود نداره که مشخص بشه مقدار runTimeInput واقعا از جنس User هست و معمولا با استفاده از validation های مختلف و factory متد ها باید مشخص کنیم. اگر بخوایم یک سناریو دیگ رو برسی کنیم که یکم پیچیده تر باشه. شما به هردلیل منطقی یا غیرمنطقی تصمیم داری یک function که در نهایت یک object هست رو serialize کنید. چطور این کار میکنید؟ function hello() { console.log("hooo"); } console.log(JSON.stringify(hello)); باتوجه به این که در #JSON به طور کلی هیچ طوره فرمت استانداردی وجود نداره برای این کار منطقی هست کد بالا کار نکنه. ( البته با trick همین کد بالا رو میتونید کاری کنید که بشه ولی کاری به اون سناریو نداریم :) ) یک سناریو پیچیده تر اینه که شما یک object داشته باشید که property descriptor های اون رو دست کاری کردین چطور میخواین بدون ست کردن flag یا نشانه در هنگام serialize کردن و بعد از دریافت همون object متوجه بشید که property descriptor رو چطور باید ست کنید. کلا بخوام خلاصه و جمع بندی کنم هرچیزی که مختص object هست که در runtime وجود داره مثل انواع reflection ها و property descriptor و method ها و ... . اینجا هست که pickel خودش رو نشون میده. import pickle class NumberOne: def __get__(self, obj, objtype=None) : return 1 class User: __name = "iman" one = NumberOne() @property def name(self): print("hello from getter") return self.__name def __eq__(self, value: object) -> bool: if isinstance(value , User) and self.__name == value.__name: return True return False def __str__(self) -> str: return f'User(name={self.__name})' def hello(): print("hello from function") # instance sterilization user_instance_bin = pickle.dumps(User()) run_time_user = pickle.loads(user_instance_bin) print("user instanceof User :",isinstance(run_time_user , User)) print("user object :" , run_time_user) print("equality check :" , run_time_user == User()) print("getter invocation :" , run_time_user.name) # function sterilization function_bin = pickle.dumps(hello) run_timefn = pickle.loads(function_bin) run_timefn() # class sterilization cls_bin = pickle.dumps(User) runtime_cls = pickle.loads(cls_bin) print("class check:" , issubclass(runtime_cls , User)) # << Exciting part >> print("WTF:",run_time_user.one) در اینجا شما هر جسم قابل لمسی رو در #Python میتونید serialize کنید و مستقیم با خوندن همون data یک object قابل لمس در runtime با تمام metadata ها دریافت کنید. از class گرفته تا یک gatter method که با decorator هست تا انواع magic method ها یا به قول #Pythonic ها dunder method. از همه جالب تر اون بخش آخر هست که یک Python Descriptor رو هم کنار object های User گذاشتیم و میبینیم اون هم به صورت کامل میبینیم. اگر بخوام خلاصه در یک جمله توضیح بدم رسما با اینکار انگار از یک object دارید فایل exe میسازید به جای یک برنامه بزرگ! نکته بعدی این که این pickel استاندارد مربوط به کد های python هست و جای دیگ تقریبا میشه گفت کاربردی نداره. https://docs.python.org/3/library/pickle.html
5
1.6K
2
18
یه فکت درمورد لینوکس هست که میگه: "همه چیز در لینوکس File هست" همین یک جمله کافی هست که متوجه بشیم تقریبا وقتی میخوایم با هرچیزی کار کنیم به نوعی با File Descriptor ها سرکار داریم. داخل پست قبل داخل عکس بالا یک نکته ای اشاره کرده بودم که File Descriptor عدد 1 چی هست؟ باهم جوابش رو اینجا برسی میکنیم. وقتی یک Process جدید در سیستم عامل ساخته میشه File Descriptor های 1,2,3 به صورت رزرو شده هستن و به به Process اختصاص داده میشوند. 0 = stdin 1 = stdout 2 = stderr داخل عکس پست قبل هرجا از fmt.Println() استفاده کرده بودیم در حقیقت داشتیم روی FD 1 مینوشتیم. به صورت خلاصه هروقت console.log میزنیم داریم روی FD 1 مینویسیم. یعنی کنسول هم یک فایل هست. این موضوع منطقی هم هست چون وقتی یک ترمینال باز میکنید اگر tty بزنید بهتون آدرس terminal باز شده رو بهتون میده که وقتی Process روش باز میکنید از طریق FD 1 و 2 شما به برنامتون input و output میفرستید و میبینید. با این تفاسیر وقتی Terminal ما یک file هست پس میتونیم با node:fs داخلش بنویسیم. import fs from "node:fs"; fs.writeSync(1, Buffer.from("Hello NodeMaster\n"));
14
1.6K
5
5
PLACEHOLDER_DOCUMENT_URL
این هم یک مثال با دیتا هست که میتونه برای درک بهتر بهتون کمک کنه
1.6K
3
باشد تا رستگار شویم.🔥 "node".split('').sort().join('')
18
1.6K
3
4
خدمت شما بگم #Deno 1.45 به تازگی منتشر شده. یکی از نکات خوبی که من در این آپدیت دیدم قابلیت Monorepo هست که اضافه شده. و البته std هم داره نزدیک به stable شدن میشه. و صد البته با فعال کردن flag زیر میتونید دسترسی به ویژگی های جدید #Deno در ورژن 2 داشته باشید. DENO_FUTURE=1 #Update
8
1.6K
1
2

دنبال یک بهانه بودم که دوتا از بزرگترین و مهم ترین کتاب های computer science رو معرفی کنم. خودم کامل نتونستم هردو رو بخونم چون به شدت سنگین هستن و وقت گیر. در این توییت به این کتاب ها با یک داستان درمورد لینوکس و شخص سازندش یعنی لینوس توروالدز اشاره میکنم نقطه مشترکشون با این کتاب ها رو میگم https://x.com/imanhpr_media/status/1854096388641996939?t=g2nNlKxcScFHFab8BUeELA&s=09 #Book
5
1.6K
27
4
خیلی از دوستانی که من میشناسم اکثرا به صورت self thought بودن و از رشته های دیگ وارد برنامه نویسی شدن. بخاطر همین موضوع ممکنه یکم سردرگمی برای دوستان پیش بیاد درمورد مفاهیم پایه ای تر مربوط به Computer science و البته شما چه frontend یا backend باشید هرچقد در این مفاهیم عمیق تر باشید در بازار کار به شما Competitive advantage میده و کار پیدا کردن برای شما خیلی راحت تر میشه و این موضوع رو هم قشنگ حس میکنید. نکته بعدی این که این مسیر به هیچ عنوان یک مسیر یک شب یک ماه و یک ساله نیست و سال ها زمان بر هست و این شما هستین که تصمیم میگرید چقدر برای شما کافی هست با توجه به علاقه شما. میتونید این ها رو ندونید و درآمد قابل قبولی هم داشته باشید ولی اگر قصد پیشرفت دارید این مفاهیم از واجبات هست. خودم هم در همین مسیر هستم و دارم یاد میگیرم و از این منابع استفاده میکنم و امیدوارم براتون مفید باشه و کورس ها و نکاتی هم که اینجا میگم باتوجه به سطحی که حس میکنید دارید انتخاب کنید و ببینید. - همیشه هروقت کسی از من درمورد مسیر Backend سوال میپرسه من تاکید خیلی زیادی روی database و database design دارم. https://downloadly.ir/elearning/video-tutorials/complete-intro-to-databases/ https://downloadly.ir/elearning/video-tutorials/complete-intro-to-sql-postgresql/ و اگر سطح خوبی دارید و میخواید deep تر بشید قطعا این چنل یوتیوب یک طلا درمورد database ها هست بیشتر از زاویه آکادمیک به مسائل نگاه میکنه و خب برای باتجربه تر ها خیلی مناسب هست. https://www.youtube.com/@CMUDatabaseGroup - موضوع بعدی networking هست. شما چه frontend باشی یا backend باید و باید OSI Model رو به صورت قلبی درک کرده باشی و البته در حد پایه ای network رو بشناسین شاید شما بگی من فرانت هستم لازم نداره. ممکنه این موضوع مستقیم تاثیری روی کار شما نداشته باشه ولی وقتی همکار devops شما اگر ازتون سوالی پرسید میتونید باهاش همکاری کنید مثل مجسمه خشک به همکارتون نگاه نمیکنید و این خیلی نکته مثبتی هست. https://downloadly.ir/elearning/video-tutorials/introduction-to-computer-networking-2-hour-crash-course/ این دوره خیلی کوتاه هست و برای خیلی ها کافی هست و بیشتر نیازی نیست پیش برید ولی برای همه لازم هست. بقیه بیشتر برای عمیق تر شدن و علاقه هست. https://downloadly.ir/elearning/video-tutorials/comptia-network-n10-008-full-course-practice-exam-1/ https://www.goodreads.com/book/show/59147607-computer-networking-global-edition این کتاب که پایین میزارم یک خورده قدیمی هست و اگر میخواید مطالعه کنید یکم دقت کنید. درکل کتاب باارزشی هست. https://www.goodreads.com/book/show/505564.The_TCP_IP_Guide در ادامه از این دو repo سعید کنید الهام بگیرد برای مطالعه و deep تر شدن. https://github.com/ossu/computer-science https://github.com/jwasham/coding-interview-university مفاهیم دیگه ای که در آینده با هم منابع مهمشون رو برسی میکنیم مثل سیستم عامل و مفاهیم low level تر مثل Computer architecture. یک نکته دیگ این که اگر حس میکنید من میتونم به شما کمکی کنم در هرموردی میتونید PV به من پیام بدین و من خیلی خوشحال میشم اگر بتونم کمکی کنم. #Course #Book #Guide
31
1.7K
80
16
درود به همگی دوستان. براتون سال خوش و پر از موفقیتی رو آرزو میکنم. امیدوارم موفق باشید.🔥
30
1.7K
2
چند روزی هست #NodeJS نسخه 22.12 LTS منتشر شده و شاهد یکی از بزرگترین قدم های #NodeJS برای آینده هستیم. در این ورژن میشه ماژول های ESM رو در CJS بدون استفاده از --experimental-require-module فلگ استفاده کرد. این موضوع باعث میشه که اکوسیستم بیشتر سمت ESM بره و استفاده از CJS کمتر بشه. https://nodejs.org/en/blog/release/v22.12.0 #Update
11
1.7K
4
یک مفهمومی در یادگیری مفاهیم عمیق وجود داره به اسم First principles thinking. خیلی خالصه میشه شکستن یک مسئله پیچیده به مسائل کوچک تر و برسی اون ها از طریق مفاهیم Fundamental. روز به روز که جلوتر میریم این موضوع کم رنگ تر و کم رنگ تر شده تا الان که باتوجه به پیشرفت LLM ها خیلی ها دیگه علاقه ای به داشتن کسب دانش عمیق درمورد یک موضوعی ندارند. جدا از این موضوع خیلی ها از قدرتی که دانش Fundamental در هر موردی بهشون میده ( در اینجا برنامه نویسی ) خبر ندارن یا علاقه ای بهش ندارن و همین باعث میشه گاهی اوقات در یک Loop ناقص از LLM های مختلف درخواست فیکس کردن باگشون رو کنن یا در فورم های مختلف به دنبال چرایی مشکلشون بگردن و هیچ وقت ممکنه به این موضوع دقت نکنن که چقدر Fundamental میتونه راه گشا باشه براشون و اگر در این مورد خوب بودن خیلی موفق تر بودن. به عنوان مثال در این سال ها کلی دوره آموزشی، مقاله، بلاگ پست، ویدیو یوتیوب، درمورد Event loop تهیه شده و همه دیدم ولی هیچکس نیومد تو این ویدیو ها به ما بگه که کل Event loop رو به صورت خیلی ساده میتونیم در همین چند خط کد #Clang ببینیم. حجم چیز هایی که میشه از این man page و این تکه کد یاد گرفت درمورد مفاهیم AsyncIO و کلا IO واقعا مثال زدنی نیست و البته همین موضوع میتونه اهمیت یادگیری مفاهیم سیستم عامل رو دوباره به ما نشون بده. گاهی اوقات بهتره وقتی یک مسئله ای داریم یک قدم عقب تر بریم و از یک زاویه دیگه بهش نگاه کنیم. حالا سوال پیش میاد خب ایمان من میخوام Fundamental قوی بشم از کجا شروع کنم؟ فرقی نداره که Frontend dev هستین یا Backend. سیستم عامل، شبکه، الگوریتم و البته برای FrontDev ها Web Api هم میشه در نظر گرفت. https://man7.org/linux/man-pages/man7/epoll.7.html
20
1
1.8K
16
PLACEHOLDER_DOCUMENT_URL
قبلا در این مثال اشاره کوچکی به File Descriptor ها باهم کردیم. امروز با هم یکم عمیق تر میشیم. قبل از هرچیزی بهتر است این موضوع را درک کنیم که وقتی از "File" در اینجا صحبت میکنیم منظور از فایل های ویدیویی و موسیقی و عکس و باینری به تنهایی نیست. در اینجا باید از زاویه دید سیستم عامل به کلمه "File" و معنی اون نگاه کنیم تا بتونیم درک مناسبی داشته باشیم. از زاویه دید OS هر File میتونه یک Directory یا نمونه های بالا که گفتم یا حتی انواع IO Device های مختلف مثل Mouse و Keyboard و البته socket رو نباید فراموش کرد. شاید گیج شده باشید یا براتون سوال پیش اومده باشه که چرا باید یک File از زاویه دید OS معادل همچین چیز هایی باشه؟ جواب خیلی ساده هست داشتن یک Abstraction خوب با یک Interface یکسان برای کار کردن با انواع مختلف IO Device ها قدرت خیلی زیادی میده و البته توسعه رو خیلی آسون تر میکنه. البته ما به عنوان Backend developer مستقیما با این sys call ها کار نمیکنیم و زبان های برنامه نویسی سطح بلاتر این موضوع رو هنوز Abstract تر کردن و یک Interface ساده تری به ما دادن. درواقع این موضوع کار توسعه دهنده زبان های برنامه نویسی دیگ رو راحت تر کرده تا برای ما بتونن راحت تر یک Interface تمیز و خوب توسعه بدن. حالا میرسیم به این که FD چیست؟ - یک عدد postive int کوچک میباشد که برای هر Process این عدد ها Unique هستن و Process ما با استفاده از این آیدی هایی که از Kernal اومده میتونه با IO Device های مختلف صحبت کنه. به عنوان مثال FD 123 در یک Process با یک سوکت اشاره داره و در یک Process دیگ به یک text file. - به صورت کلی File Descriptor ها بخشی از POSIX Api هستن و سیستم عامل های UNIX-like دارن. - روی ویندوز داستان ظاهرا متفاوت هست و یک مفهومی به اسم Handle دارن که جزیاتش رو زیاد نمیدونم و در آینده باهم یادمیگیرم. اگر هنوز یکم درک موضوع Abstraction که بالاتر اشاره کردم براتون سخته. مثال جذاب زیر براتون روشن میکنه داستان رو. package main import ( "fmt" "net" "os" ) const MY_TXT = "NodeMaster Is Alive!" const WRITE_NET = "WRITE TO TCP SOCKET" const WRITE_FILE = "WRITE TO FILE" func main() { fd, _ := os.OpenFile("myTest.txt", os.O_CREATE|os.O_APPEND|os.O_WRONLY, 0644) nt, _ := net.Dial("tcp", "localhost:3000") fmt.Println(WRITE_NET) nt.Write([]byte(MY_TXT)) fmt.Println(WRITE_FILE) fd.Write([]byte(MY_TXT)) fmt.Println(nt) fmt.Println(fd) } اینجا یک برنامه #Golang خیلی ساده داریم که یک فایل معمولی باز میکنیم و یک tcp socket و MY_TXT رو داخل هردو این ها Write میکنیم و چندتا لاگ ساده داریم که کارمون راحت تر باشه برای پیدا کردن syscall ها برنامه رو build بگیرید و با command زیر برنامه رو اجرا کنید. در حقیقت وقتی سوکت و یک فایل متنی روی دیسک باز میکنیم اون پشت syscall مربوطه به ما یک File Descriptor میده که میتونیم با اون کار هامون رو انجام بدیم. strace ./main این strace به ما کمک میکنه که syscall هایی که برنامه ما انجام میده رو trace کنیم. در عکس بالا ما چندین write syscall رو میبینیم که به عنوان arg اول یک File Descriptor میگیره و به عنوان arg دوم یک بافر دیتایی که ما میخوایم داخلش بنویسیم. در شماره یک که ما عدد 6 رو میبینیم این 6 در حقیقت به یک tcp socket اشاره داره و در شماره دو داخل عکس عدد 3 به File descriptor مربوط به text file ما روی دیسک اشاره داره. همینطور که میبینید حتی داخل عکس هم بدون دونستن این موضوع اگر نگاه فقط به singture فاکنکشن write کنید از روی file descriptor ها به هیچ عنوان متوجه نمیشید که مقصدی که داخلش write میکنیم آیا یک socket هست یا یک فایل روی دیسک یا هر IO Device دیگه ای و دقیقا همین موضوع اون چیزی هست که ما میخوایم و میشه همون Abstraction که بالاتر درموردش صحبت کردیم. یک نکته این که درسته در #Golang و #Java ما Writer و Reader اینترفیس داریم و حتی اگر سیستم عامل همچین قابلیتی به ما نمیداد دوباره همچین interface هایی وجود داشت ولی کار توسعه دهنده های این زبان ها بسیار سخت تر بود برای ایجاد این interface ها. حالا دوتا نکته که دوست دارم داخل گروه نظرتون رو بگید و درموردشون صحبت کنیم. 1. داخل عکس بالا چندتا write دیگ هم داریم که عدد 1 رو به عنوان File descriptor استفاده کردن. حالا این عدد 1 چی هست؟ داخل گروه خوشحال میشم درموردش صحبت کنیم. 2. چرا از #Golang استفاده کردیم برای مثال؟ بعد از مدت ها این اولین پست من هست امیدوارم براتون مفید باشه و خیلی خیلی ممنونم که همیشه همراه من بودید و امیدوارم همگی موفق باشید رفقا.
14
1.8K
25
1
هم اکنون با این ابزار جدید میتونید #TypeScript رو به #Lua تبدیل کنید. اگر براتون سوال هست که کجا میتونه کاربرد داشته باشه این میتونه باشه که با #Lua میتونید به عنوان مثال برای #Redis اسکریپت بنویسید و حالا میتونید این کار رو بدون یاد گرفتن #Lua و با نوشتن #TypeScript و گرفتن خروجی #Lua انجام بدید. هرچند من شخصا طرفدار این موضوع نیستم ولی جالبه. https://typescripttolua.github.io/ #NodeWeekly
4
1.8K
13
7
درود دوستان ارادتتتت. خیلی وقت بود میخواستم این ویدیو رو بگیرم. روزی که من #Python گذاشتم کنار و حرفه ای شروع به کد زدن #JavaScript و #NodeJS کردم همیشه هروقت باکسی بحث برنامه نویسی میشد من این رو میگفتم که جای یک چیزی مثل Context Manager مثل پایتون در اکوسیستم #JavaScript واقعا خالی هست. وقتی #TypeScript ورژن 5.2 منتشر شد و این syntax رو برای بار اول دیدم واقعا خوشحال شدم async function main() { using resource1 = getResource() await using resource2 = await getResource() } در این ویدیو به Explicit Resource Management در زبان های برنامه نویسی #python , #golang و #cpp میکنیم. با یک پترن خیلی قدیمی به اسم RAII پترن آشنا میشیم و در نهایت میرسیم به ارتباط RAII پترن در C++ در #Typescript . این ویدیو قرار هست در دو پارت منتشر بشه و پارت دوم رو کامل درمورد مثال های عملی #Typescript گذاشتیم و تمرکز ویدیو اول هم بیشتر نگاه به زبان های دیگر و برسی این موضوع که چرا به "using" نیاز داریم. https://youtu.be/0CG_WA6Yu9o?si=QYunevpiEyWp6gWW
13
1.9K
9
8
ما Developer ها به Magic عادت داریم. بیشتر وقت ها کدی که مینویسیم فقط میخوایم کار کنه. اما چطور کار کردن اون کد خیلی اهمیتی نداره تا وقتی که کدمون کار میکنه. حالا چه به صورت جادویی کار کنه چه با جزئیات کامل بدونیم پشت پرده چخبر هست. گاها بعضی از این جادو ها اینقدر پیچیده و ترسناک به نظر میان که اصلا بهشون نزدیک نمیشیم. یکی از این Magic ها Promise ها در #JavaScript هست. اکثرا فکر میکنیم یک چیزی هست که داخل گوشت و وجود #JavaScript فرو رفته و به هیچ عنوان نمیشه تغییرش داد یا اگر هم بشه خیلی سخت هست. کاری به پیاده سازی اصلیش امروز نداریم. امروز بعد از این مقدمه طولانی میخواهیم باهم یاد بگیرم چطور یک Object بسازیم که شبیه به Promise عمل میکنه. یعنی میتونیم await کنیم اون رو با وجود این که اصلا اون Promise نیست و یک Object ساده هست. به این کد پایین دقت کنید. const thenable = { then(resolve, reject) { setTimeout(() => resolve("Hello from thenable!"), 1000) }, } const txt = await thenable console.log(txt) معمولا اولین واکنش افراد به این تکه کد "WTF" هست. داستان از این قرار هست که خیلی قبل تر از این که Promise ها به صورت استاندارد وارد #JavaScript بشن پیاده سازی های مختلف ازش وجود داشته و هرکدوم implemention detail خاص خودشون رو داشتن ولی طی گذر زمان بلاخره رسیدن به این interface که الان داریم هر روز باهاش کار میکنیم ( تقریبا شبیه به وضعیت decorator ها و پروپزوال مربوط بهش ). بزارید یکم بیشتر وارد داستان بشیم. برای این که بتونیم یک object رو await کنیم لزوما نیازی نداره حتما یک instance از Promise باشد. بلکه هر object که Promise-like باشد میتواند await بشود. این تعریف دقیقا تعریف Duck-typing هست که قبلا مفصل درموردش حرف زدیم. حالا سوال پیش میاد که Promise-like یعنی چی؟ - هر class که thanable interface را implement کند میتوان آن را await کرد. پس میتونیم نتیجه بگیریم که همه Promise ها thenable هستند ولی همه thenable ها Promise نیستند. حالا میرسیم که thanable interface چیست؟ در ساده ترین حالت دقیقا مثال بالا رو در نظر بگیرد. یک object یا class که then method رو که با دوتا argument که هردو callback هستن یکی برای وقتی که reject شده و یکی برای وقتی resolve میشه invoke میشود و ما میتونیم با اون دوتا رفتاری که Promise-like هست رو از خودمون نشون بدیم. حالا این ویژگی به ما اجازه داده که پکیج های معروفی مثل promise-retry ببینیم یا حتی یکم تلاش کنیم به کمک Promise-like ها در ES5 بتونیم چیزی شبیه بهش رو داشته باشیم که البته این موضوع خودش یک بحث دیگس اگر دوست دارید نگاهی به promise-polyfill یا babel-polyfill بندازید. این هم پست مربوط به duck typing به نظرم نگاهی بندازید: https://t.me/NodeMaster/128
11
1.9K
5
1
درود دوستان امیدوارم حالتون خوب باشه. به عنوان Backend developer از موضوعاتی که حتما باید حداقل آشنایی کوچکی داشته باشید کار کردن با container ها هست. به طوری که حداقل بتونید پروژه خودتون رو به راحتی containerized کنید. در این مورد زیاد course دیدم معمولا خیلی از کورس ها اضافه گویی میکنند و تایم زیادی هم لازم دارن. این کورس از Brian Holt از محدود course هایی هست که این اضافه گویی ها رو نداره و البته موضوع خیلی جالب و مهمی هم که اشاره میکنه این هست که کلا قبل از این که وارد بحث docker بشه با cgroup و namespace سعی میکنه یک نسخه ساده از docker رو ایجاد کنه و همین موضوع خیلی بهتون دید بهتری نسبت به این تکنولوژی میده. - این course برای افراد مبتدی مناسب هست. - این course برای افرادی که docker بلد هستن و میخوان شروع کنن داکیومنت docker رو بخونن و عمیق تر بشن ولی قبلش نیاز به یک review دارن بسیار پیشنهاد میشه. - برای دوستانی که Advance هستن ممکنه چیز خاصی یاد بهشون اضاف نکنه و تکرار چیزایی باشه که بلد هستن. پس اگر از این دسته افراد هستین حتما دقت کنید. https://downloadly.ir/elearning/video-tutorials/complete-intro-to-containers-v2/
19
1.9K
38
23
درود دوستان امیدوارم حالتون خوب باشه. حدود یک ماهی هست هیچ مطلبی رو باهم برسی نکردیم. خواستم بهتون خبر بدم مدتی هست من با استرس شدیدی درگیر شدم و کلا توانایی تولید محتوا مثل قبل رو ندارم. از این بابت من از شما معذرت میخوام. و یه صورت موقت مدتی داخل چنل نمی نویسم ولی گروه فعال هستم جدا از این مسائل ولی هروقت اگر حس کردید من میتونم بهتون کمک کنم pv به من پیام بدین قطعا جواب میدم. امیدوارم موفق باشین❤️
42
1.9K
10
28
یک پکیج خیلی کوچیک و کاربردی که میتونید در پروژه های خودتون و حتی Github action استفاده کنید تا اگر مشکل امنیتی در ورژن مورد استفاده شما در #NodeJS وجود داره با خبر بشید و در صورت نیاز آپدیت کنید فقط کافی هست که با npx این پکیج رو ران کنید. npx is-my-node-vulnerable https://www.npmjs.com/package/is-my-node-vulnerable
12
1.9K
14
داشتم داکیومنت مربوط به #Docker میخوندم یک چیزی نظرم رو خیلی جلب کرد و توضیح مربوط به "-i" بود. https://docs.docker.com/reference/compose-file/services/#stdin_open من همیشه فکر میکردم برای این که دوتا Process بتونن باهم از طریق چنل های stdin و stdout ارتباط بگیرن نیاز دارن که رابطه Parrent and Child باهم داشته باشند که خب اشتباه میکردم. اشتباه به این بزرگی که اصلا دقت نمیکردم که pipe ها در #Linux اصلا ارتباط Parrent و Child ندارند ولی روی stdin و stdout دارن با هم ارتباط میگیرن. بزارید این موضوع رو با مثال ببینیم یک کنجکاوی جدید هم برای آینده ایجاد کنیم. یک ترمینال باز کنید و "ps" رو بزنید که PID مربوط بهش رو دریافت کنید. همونطور که میدونید هر Process هم 3 تا FD به صورت استاندارد برای stdout, stdin, stderr داره. حالا اگر ما یطوری PID مربوط به terminal رو داشته باشیم باید بتونیم روی چنل stdin اون Process دیتا ارسال کنیم و روی ترمینال ببینیمش. اینجا هست که در لینوکس "/proc" میاد وسط در این دایرکتوری میتونیم اطلاعات زیادی درمورد وضعیت کرنل بگیریم و یکی از کاراش این هست که میتونیم اطلاعات درمورد Process ها درموردش ببینیم با استفاده از فرمت زیر. /proc/PID قبل تر باهم PID مربوط به ترمینالی که باز داریم رو گرفتیم حالا اگر بخوایم میتونیم از اینجا به stdin اون Process دسترسی داشته باشیم باتوجه به این که fd استاندارد stdin برای تمام proccess ها 0 هست. /proc/4561/fd/0" خب حالا به عنوان مثال اگر برنامه زیر رو اجرا کنید میبینید که داخل stdin ترمینال شما بدون ارتباط Child and parrent از طریق stdin channel تونستید دیتا ارسال کنید. import fs from "node:fs"; const stdinFd = fs.openSync("/proc/4561/fd/0", fs.constants.O_WRONLY); fs.writeSync(stdinFd, Buffer.from("echo Write To stdin - NodeMaster")); fs.closeSync(stdinFd); نکته این هست که Sky is the limit. به عنوان مثال میتونید کار سم کنید که http request از طریق stdin بفرستید و response رو از stdout بخونید. البته رابطه child and parrent همونطوری که تقریبا داخل docker هم میبینیم میتونه بهمون دسترسی بده که این چنل ها رو در دسترس بزاریم یا نه همونطوری که اگر "-i" استفاده نکنیم این چنل در دسترس نیست از طریق داکر. یک طوری مثل عوارضی بزرگ راه در نظر بگیرد. این کار همینطور که میدونید به نوعی IPC هست اما اینجا یک سوال پیش میاد. - وقتی نیاز نیست که دوتا Process رابطه Child and parrent داشته باشند تا روی stdin و stdout باهم ارتباط بگیرن. پس کجا محدودیت ایجاد میشه که این دوتا Process نتونن با هم روی این چنل ها ارتباط برقرار کنند؟ اینجا هست که یک ویژگی در کرنل لینوکس به اسم Namespace به ما کمک میکنه که مجموعه های مختلف از Process های ایزوله داشته باشیم و Process که در یک Namespace وجود دارند، نمیتواند با یک Process دیگر که در Namespace دیگر وجود دارد ارتباط روی stdout , stdin چنل بگیرد ( مگر socket ) منطقی هم هست چون namespace رو میشه دوتا machine مختلف در نظر گرفت تقریبا.( این موضوع درست مطلق نیست و بیشتر برای تصویر سازی هست ) حالا میخوام برگردم به مثال بالا اگر دقت کنید من مثل یک فایل رفتار کردم با fd/0. حالا با وجود این فکت که تمام IO device ها به نوعی فایل هستن میتونیم "lsusb" بزنیم فایل مربوط به کیبورد خودمون رو پیدا کنیم و براش درایور بنویسیم. که یک Process دیتا رو از روی کیبورد وقتی تایپ میکنیم بگیره و از طریق stdin مربوط به ترمینال تایپ کردن ما رو بفرسته برای TTY. این یکی رو واقعا دقیق نمیدونم چطور کار میکنه. حتی شاید این جمله یکم اشتباهات هم داشته باشه. ولی در کلیات حس میکنم اون پشت همچین اتفاقی داره میافته. که قطعا یک روز باهم دقیق برسیش میکنیم.
20
2.1K
13
یکی از بچه های فعال تو گروه خودمون داخل شرکتشون دنبال یک همکار جدید میگردن. دوست داشتین رزومه خودتون بفرستین. https://jobinja.ir/companies/concept-x/jobs/AT2K?_gl=1*z5obhf*_ga*MTU2MzU0NzAzOC4xNzEzMDkxOTU2*_ga_T8HC2S1534*MTczNDQ2MDE1MC41LjEuMTczNDQ2MTMyNS4yNS4wLjA. #Work
2.1K
4
3
درود و وقت بخیر دوستان. فرصت شغلی از بچه ها گروه خودمون دنبال همکار میگردن. دوست داشتین نگاهی بندازین. https://jobinja.ir/companies/baro-sazan-liyan-amiri/jobs/AZJ6 #Work
1
2.2K
1
7
درود و وقت همگی بخیر امیدوارم حالتون خوب باشه. بچه هایی که تازه کار هستن و #Backend رو مدت کمی هست کار میکنن ممکنه یکم براشون سوال باشه که به صورت کلی یک سیستم چه چیزهایی رو دارد و چطور این ها باهم کار میکنند. به جواب رسیدن برای هرکدوم از این سوال ها زمان زیادی ممکنه از ادم بگیره اگر راهنما خوبی هم وجود نداشته باشه. پیشنهاد میکنم این دوره رو حتما ببینید. https://downloadly.ir/elearning/video-tutorials/system-design-for-beginners/ بهتون دید خیلی خوبی میده که چه چیزایی رو حداقل باید بدونید و میتونه به عنوان یک Roadmap هم بهش نگاه کنید که در آینده در هرکدوم از بخش های مختلف این آموزش عمیق تر بشید. اگر باتجربه تر هم هستید و سیستم دیزاین نیاز به refresher دارید یا کلا تا حالا کار نکردین شروع خوبی میتونه باشه.
22
2.3K
60
4

Listing Statistics
170
2 months ago
SeBuDA
Recently our headquarters moved from USA to Netherland so we could make more features for our users, we sure that our users can feel the changes in the future and this decision is for sake of our users
Netherland
Sebuda B.V.
CoC Number: 95490469
Zuid-Hollandlaan 7, 2596AL ‘s-Gravenhage
The Hauge, The Netherlands
(+31)0687365374
Be with us on Social Networks
Social media accounts for sale
Help and Services
© 2022 SeBuDA.com, All rights reserved.